
探寻社交网络中的关系: 统计网络模型初探
在上一章当中,我们对于网络的基本知识进行了介绍,这些知识构建起了网络科学的基础,同时也孕育着巨大的潜能。社会科学追求理论的建构,但疏于思考理论层次的丰富性。以社会学为例,一度在宏大理论和抽象实证主义之间摇摆(参见米尔斯所著《社会学的想象力》)。大数据时代的到来,再一次使得少数人开始对理论的认识产生动摇,以为只要把握住数据就足够了。这与可计算性社会科学都是相互矛盾的。可计算性社会科学研究社会现实,紧紧抓住数据,但是绝不束缚于数据。
数据(data)、模式(pattern)、法则(law)、机制(mechanism)和隐含的原理(principle)构成了科学研究等级,如图11-1所示。科学理论的等级在这里又被粗略地划分为四个等级:模式、法则、机制和原理。网络科学以关系来度量物理世界和社会现实(social reality)。这些稳定的关系——表现为网络中的链接——构成了网络科学可计算性的基础。沿着网络中的链接出发,网络科学正在尝试突破社会现实混沌的迷宫,从社会现实的数据出发,发掘社会系统内部的模式、法则、机制、原理。
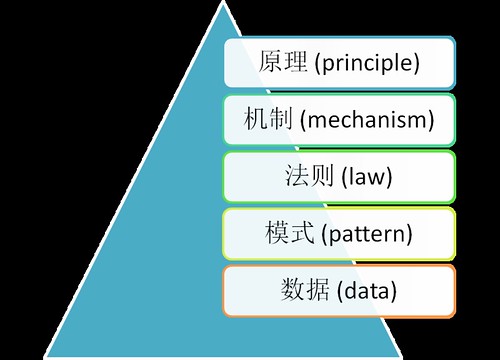
图 11-1. 科学研究的金字塔
网络科学所采用的方法非常多样,除了经典的统计方法之外,很多物理学的方法也被广泛的应用在网络研究当中。具体而言,网络科学有两个方法来源,一个是传统的社会网络分析,一个是近十几年里面迅猛发展起来的复杂网络研究。这两股研究的脉络构成了网络科学的两条主线。网络科学已经走出传统的社会网研究的藩篱。互联网浪潮的袭来推动传统网络研究与互联网科学(web science)的融合。一种以复杂网络(complex network)为代表的新型网络科学开始迅速成长(Barabasi, 2003)。例如,巴拉巴西等人采用动力系统的研究方法分析复杂网络的增长机制(Barabási & Albert, 1999)。但在本章当中,我将主要关注统计网络模型(statistical network models),并通过介绍处理社会化网络数据的例子来深化我们对于网络的认识。
本章的结构安排如下:一、通过介绍网络科学的异军突起来思考可计算性在不同学科的发展,以便于启发我们对于可计算社会科学的认识;二、我们介绍数字化媒体的发展,以及由此带来的大数据浪潮的挑战和机遇;三、我们开始介绍网络链接的属性,拓展对于网络的认识;四、简略介绍QAP检验;五、介绍指数随机图模型;六、结论和讨论。
- 网络科学的异军突起:反思可计算性
- 数字化媒体和大数据
- 扩展对于网络的认识(二模网络与多模网络和时间序列网络)
- QAP检验
- 指数随机图模型(ERGM)
- 一条开放的道路
一、网络科学的异军突起:反思可计算性
事实上,作为一个后起之声,可计算性社会科学(computational social science)已经在各个分支学科和新的交叉性学科中如火如荼!关于计算社会科学的介绍可见Lazer等人(2009)发表在《科学》杂志上的一文。Lazer等人综述了可计算性社会科学的涌现和发展,尤其强调了网络科学研究在其中所扮演的角色和数字媒体所提供的机遇。网络科学和可计算性社会科学的兴起都使得我们开始更加严肃地思考可计算性在科学版图当中的作用。
对于可计算性的追求在自然科学一直是主流。物理学具有着最强的可计算性。物质世界的稳定性给了物理学发展提供了得天独厚的条件。物理学家采用各种稳定的手段测量物理世界的状态:长度、面积、体积、质量、速度、时间、能量。从牛顿力学到相对论,电磁学、再到量子力学,物理学展现了理论和数据的高度统一:我们可以精确地知道桥梁的重量、地球到月球的距离和卫星发射的速度。这种成就在一开始就激励着社会科学的发展。生物学诞生之初,研究者多少博物学家,忙着收集标本,区分生物所属的界、门、纲、目、科、属、种的类别。即使到了达尔文提出物种起源假说,生物学的发展依然备受局限。是什么使得生物学步入可计算化的路径,进而实现新的飞跃?一个可能的答案是“基因”。抓住这个计算性的本源,生物学开始迅速崛起。
社会科学则是另一番图景。试思考为什么经济学是社会科学中发展较好的?答案是货币。用货币度量经济行为使经济学具有了天然的可计算性;其次是心理学,不是量表,而是实验,使得心理学具有了“模糊的”比较能力。而其他传统的社会科学,如传播学,则处于摇摆当中缓慢发展。
值得注意的是三个迅速发展的学科:计算机科学、统计语言学、和我们正在谈论的网络科学。毋庸置疑,计算机科学是二十世纪发展最快的学科之一。其中一个重要的原因就在于计算机科学所对付的对象是离散的0和1。0和1通过二进制的运算构成了现代计算机的基础,也使得计算机科学从诞生之初,其“基因”当中就蕴含了强大的可计算性。在此基础上,计算机科学可以相对容易地与数学相结合研究信息和通信问题,并借助计算性思维(computational thinking)通过算法设计来自动化地解决问题(Wing, 2006)。统计语言学是传统语言学与计算机科学相互融合的结果。通过建立关于语言学的数学模型,并通过计算机来进行运算,统计语言学使得语言学在过去的三十年当中取得长足进步(吴军, 2012),例如自然语言处理(natural language processing)已经广泛地应用在互联网产业当中和其他学科的研究当中。最近升起的新星则当属网络科学。网络科学对社会关系进行运算,借用统计物理的方法,很快发现复杂网络(例如,大规模的社会网络就是一种复杂网络)具有明显的小世界特征(Watts & Strogatz, 1998)和无标度特征(Barabási & Albert, 1999)。
概括以上内容,我们可以发现:可计算性植根于不同的学科当中。发掘可计算性对于不同的学科具有举足轻重的意义。基于可计算性的研究才有较高的信度和效度,才能得到更确实的(solid)发现,才能和数学工具和物理学工具更好的结合,才能更深刻地探寻社会模式背后的法则、机制、规律。
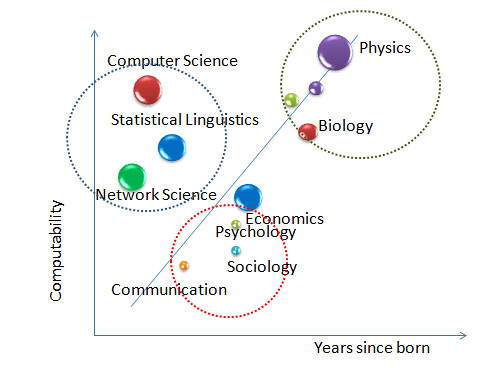
图 11-2. 学科历史与其可计算性的关系
二、数字化媒体和大数据
互联网的发展使得人类社会进入了一个新的时代:数字媒体时代(the era of digital media)。这种变化的影响已经被诸多预言者和研究者所分析,也为这个时代的个体所体认与观察。人类的交往模式,商业行为,舆论空间等,都因互联网而改变。但本文由数字化痕迹开始讲起。
数字化媒体(digital media)的崛起正在深刻变革的社会科学的研究视野。因为数字化技术的发展(比如互联网)使得很多的人类行为变得可以观察,因而给我们更真实地认识世界提供了一个崭新的入口——数字化痕迹(digital traces)。比如,你在网络上购物的经历,你在社交媒体上的使用记录。这些数字化痕迹(又称数字化指纹(digital fingerprint),或数字化脚印(digital footprint)),使得研究者可以追逐这种痕迹,分析其行为背后隐藏的社会规律,进而提供了一个巨大的资源。这种资源的出现正在变革着不同学科的研究视角和研究疆域。比如,网络化的大规模数据的数字化痕迹(digital traces)第一次使得传播行为获得了计算性。而记录(document)、收集(collect)、分析(analyze)、可视化(visualize)这些传播行为就成为了计算传播学的主要工作。按照这个设想,社会科学必须走出传统的研究套路,获得在网络上保存、抓取、分析、可视化大规模电子化数据的能力,也需要支持这些工作的工具。毫无疑问,社会科学因此将和计算机科学开始交汇,至少需要程序员投入到这种大规模数据的挖掘工作中来。计算机科学家越来越将更多的注意力放在社交媒体的使用研究方面来。一系列的计算机会议以社交媒体研究作为重心。其它的学科分支也马上意识到互联网带来的机遇和挑战。这里要首先谈人类认知世界的一个重要方法——观察法。
观察法是社会研究和自然研究最古老的方法。在社会研究领域,这种方法因其复杂和难以操控,往往只是适用于研究初期。研究中后期往往使用调查和实验方法,但后面这两种方法的优点是根据研究者的视角进行操控(manipulate),但缺点也在这里。因为访谈或问卷或实验,往往会降低研究的效度。而数字化痕迹使得这种限制减少,使得研究者真正在研究活生生的人类行为,并且研究的规模非常巨大,且往往具有时间序列的信息。数字化痕迹使得非介入的观察(unobtrusive observation)成为可能,因而给研究者带来的巨大的机遇。机遇是数据的获取为检验和发展经典理论提供了土壤。但同时也伴随着挑战。这种挑战则首先主要来自这种数字痕迹的获取、分析和储存上。
当然第一关是数据的获取。资源虽然存在,却并不能为所有的人所使用。因为这里有一个天然的、历史原因造成的技术屏障——计算机技术。数字化痕迹的还有一些其它特点。比如规模巨大,难以分析,当然这涉及到数据的分析问题,不是本文的重点。另外一个方面,这些数字指纹往往是流数据,这意味着如果此刻不获取这些数据,过一段时间这些数据就很难或者没有可能获取了。甚至因为数据规模庞大,一些互联网公司也并不会储存所有的数据。这也为数据获取者提供了一种学习的急迫性。
其中最简单的是研究者的编程技术。传统的社会科学研究者和读者往往忽略计算机技术尤其是编程能力的培养。因而,在学科转型之初,第一步就是这种开始学习崭新的东西。这多多少少让新手感到畏惧。需要指出的是,这种畏惧是不必要的。因为技术的发展趋势是越来越人性化和具有可读性。这给编程语言的学习带来便利。社会科学研究者可以选取简单的编程语言(R、Python、Ruby)开始计算机编程的学习。一个问题是是否可以采用即成的数据抓取软件呢?我的理解是,就目前而言,打包好的数据抓取软件过于死板,且效率低下,并且多数价格不菲、不是开源的软件。因而不是首选。现在很多统计语言往往也可以从事数据抓取的工作,比如R社趣发展了twiiteR的包和Rweibo的包。虽然其接口并不完善,但研究者根据自我需求进行自由的开发。
社交网站为了自身的发展,往往选择向外界开放部分资源,以方便第三方发展基于该社交网站的产品,进而更好吸引使用者使用。比如新浪微博上有着纵多的应用,这些应用的数据接口就是由新浪微博所提供的。当然这种数据提供需要注册和认证,例如,对新浪微博而言可到应用开发页面注册 。因而,数据抓取的第一步,就是建立数据连接的工作,以获取社交网站开放数据流的许可。现在流行的方式是使用OAuth获取连接社会化媒体的API的使用权限。这种机制的好处是直接从网站数据库获取数据,因而数据结构化较好,不需要经过复杂繁琐的处理。且更好保护了使用者的隐私(Russell, 2011)。获取数据使用许可之后,其使用就非常方便灵活了。
在本章当中,我们使用李舰 (Li, 2013)编写的Rweibo来连接新浪微博的API接口,并获取我们所需要的信息。Rweibo是一个新浪微博针对R语言的软件开发工具包(Software Development Kit, SDK)。作为一个R的软件包,Rweibo可以在R软件当中自由安装和调用。
新浪微博的API的使用需通过OAuth的方式进行授权。使用者需要首先到新浪微博开放平台申请一个新的应用:在新浪微博应用页面(http://open.weibo.com/development)点击“创建应用”并选择“网页应用”。创建应用后,在应用信息中可以找到该应用的App Key和App Secret。在本章当中我们创建一个应用名称为cssbook的应用。
注意:Rweibo的授权回调页在R软件中默认为http://127.0.0.1/library/Rweibo/doc/callback.html,不允许用户修改。所以在创建应用的时候要一定要设置“授权回调页”为这个页面。否则,会造成授权回调页不匹配的错误。
然后在R软件中通过Rweibo软件包通过编写R脚本来连接新浪API接口并进行数据获取等各项操作。第一步是在R软件当中安装Rweibo这个软件包。因为Rweibo使用过程中还会用到其它几个相关的包,如RCurl、rjson、XML、digest,在此也一并安装。
# R程序11-1:在R软件当中安装并调用Rweibo软件包
install.packages("Rweibo", repos = "http://R-Forge.R-project.org")
library(Rweibo)
# 使用Rweibo还需要安装其它几个相关的R包
install.packages("RCurl")
install.packages("rjson")
install.packages("XML")
install.packages("digest")
第二步是在R当中输入App Key和App Secret进行OAuth认证。执行以下R代码。
注意:createOAuth代码中的access_name必须改成你自己的新浪微博账号。
# R程序11-2:在R中进行OAuth认证
registerApp(app_name = "cssbook", app_key = "307359760", app_secret = "82dfbc7194b2f3c37029b9f8c880c385")
roauth <- createOAuth(app_name = "cssbook", access_name = "wangchj04")
# 一定要将网页应用的“授权回调页”设为:http://127.0.0.1/library/Rweibo/doc/callback.html
这样,在执行createOAuth代码后,就会自动弹出一个授权网页。在用户授权后,就会转到包含CODE的授权回调页,复制该页面的CODE并粘贴到R界面(R console),单击回车键,就可以完成授权。
小练习:向R软件提问:用户可以通过listApp(“cssbook”)命令查看这个应用的信息;如果用户需要删除这个注册,可以执行deleteApp(“cssbook”)。当然,用户还可以通过执行modifyApp()命令来修改关于这个应用注册信息。要了解关于modifyApp的用法,读者可以在R界面中输入?modifyApp来查看其使用方法。当然,如果读者对于其它的R命令的使用不熟悉,也可以使用这个方法问一下R软件。
在成功通过OAuth2.0认证之后,用户就可以较为自由地调用和使用Rweibo的相关命令。以下R程序展现的是如何查看OAuth的注册信息、API的权限设置、查看用户关注的朋友所发布的微博、自己通过Rweibo发布一条测试信息。
# R程序11-3: 测试Rweibo
# 查看所注册的OAuth的信息
roauth
# 查看API权限设置
roauth$getLimits(TRUE)
# 查看自己所关注的朋友所发布的信息
sf = statuses.friends_timeline(roauth, count = 5)
sft[[1]]
# 发布一条微博
su <- statuses.update(roauth, status = "Test Rweibo for cssbook")
# 获取一条微博的被转发列表
# 这条源微博为:http://weibo.com/1869170057/zvzbUqqwC,查看页面源代码可以找到其mid
ana1 <- analysis.getReposts(roauth, mid = "3575234466298494")
通过analysis.getReposts命令,我们获取了@统计之都在新浪微博上所发的一条微博的转发列表,该微博位于http://weibo.com/1869170057/zvzbUqqwC,通过查看该页源代码可以找到这条微博的mid为3575234466298494。使用names(ana1)命令,可以查看数据ana1当中的变量信息。该数据主要包括两大部分信息:一部分是微博转发信息,包括转发时间、转发微博mid、转发微博内容text、转发微博再次被转发数量、转发微博被评论数量等。如下所示:
"created_at", "mid", "text", "reposts_count", "comments_count",
"attitudes_count", "in_reply_to_status_id",
"in_reply_to_user_id","in_reply_to_screen_name"
另一部分信息为转发者信息,包括转发者的user id,转发者的screen name、转发者的地理信息、转发者的性别、转发者的粉丝数量和朋友数量等。具体信息如下:
"User_idstr", "User_screen_name","User_province", "User_city",
"User_location","User_description", "User_gender", "User_followers_count",
"User_friends_count", "User_statuses_count", "User_favourites_count",
"User_geo_enabled", "User_created_at", "User_following", "User_follow_me",
"User_bi_followers_count", "User_verified", "User_verified_type",
"User_verified_reason"
我们将转发源微博的微博称之为“转发微博”。那么,值得注意的是analysis.getReposts命令获取的是一个转发列表,即所有的转发微博和转发者的信息,但我们仍然不知道具体的转发网络。
就新浪微博单条微博而言,获取转发网络有两种方法:第一种是将所有的转发微博的被转发情况再抓取一次,这种方法的有点是精确,缺点是需要多次调用API接口;第二种方法是解析(parse)转发微博的内容,如果转发者不修改上家的转发内容的话,比如一个转发微博的内容为:“//@黠之大者: 我喜欢使用R软件。”我们可以认为这条微博转发自微博用户“黠之大者”。这种方法的优点是不需要继续调用API接口,缺点是会由于转发者修改转发内容,尤其是删除其转发源,而造成错误的结果。
在本章当中,我们主要使用第一种方法。但我们不需要把所有的转发微博都再抓取一次,因为analysis.getReposts命令已经可以使我们知道每条转发微博之后的被转发次数。具体而言,只有那些reposts_count大于零的转发微博之后被其他用户转发。就我们这个具体的例子而言,1020个转发微博当中(870个独立转发者),只有139个转发微博被再度转发。86.4%的转发产生于第一步转发(即不经过中间转发者而直接转发源微博)。
# R程序11-4:抓取二度转发者id
ana2 = subset(ana1, ana1$reposts_count!= "0")
offspringlist = list()
for (n in 1:length(ana2$mid)){
counts = ana2$reposts_count[n]
result = statuses.repost_timeline(roauth, id = as.character(ana2$mid)[[n]], count = counts )
for (m in 1:counts){
offspring = result[[m]]$user$idstr
addin = c(n, m, offspring)
offspringlist = rbind(offspringlist, addin)}
}
data = data.frame(offspringlist, nrow=262, byrow=T)[,1:3]
names(data) = c("n", "m", "offspring")
# 二度转发的源头
dat = data.frame(ana2$User_idstr)
dat$n = c(1:length(ana2$User_idstr))
names(dat) = c("source", "n")
dats = merge(dat, data, by = c("n"))
dat1 = dats[,c('source','offspring')]
我们已经获取了所有的转发微博被再度转发的网络。对于所有的转发者而言,必然存在一个来源。如果一个节点在二度转网络当中没有来源,那么它的来源节点就是原微博的作者。由此,我们可以进一步获得一度转发网络:
# R程序11-5: 获取一度转发网络
# 每个节点都有来源,如果一个节点无来源,则来自源节点1869170057
idsUnique = unique(ana1$User_idstr)# 870 unique diffusers
offspring = subset(dats$offspring, dats$offspring != dats$source)
idsWithoutSource = subset(idsUnique, !(idsUnique %in% offspring) )
dat2 = as.data.frame(cbind(1869170057,idsWithoutSource))
names(dat2) = c("source", "offspring")
# 合并一度转发网络及二度转发网络
dat3 = rbind(dat1, dat2)
基于总的转发信息和二度转发信息,我们可以绘制转发网络。
# R程序11-6:绘制转发网络
# 绘制总的转发网络
library(igraph)
g<-graph.data.frame(dat3)
l<-layout.fruchterman.reingold(g)
# 明确节点属性
vertex<-as.numeric(V(g)$name)
V(g)$size = log(degree(g, v=V(g), mode = c("out")) + 1 )
nodeName = unique(ana1[,c("User_idstr", "User_screen_name")])
node = as.data.frame(V(g)$name)
names(node) = c("User_idstr")
nodeLabel = merge(node, nodeName, by = "User_idstr", sort = F)
nodeLabel$nodeSize = V(g)$size
nodeLabel$User_screen_name[nodeLabel$nodeSize < 1]=""
nodeLabel = nodeLabel$User_screen_name
# 保存图片格式
png("d:/repostGraph.png",
width=5, height=5,
units="in", res=700)
plot(g, vertex.label= NA,edge.arrow.size=0.02,vertex.size = 0.5,
layout=l )
# 结束保存图片
dev.off()
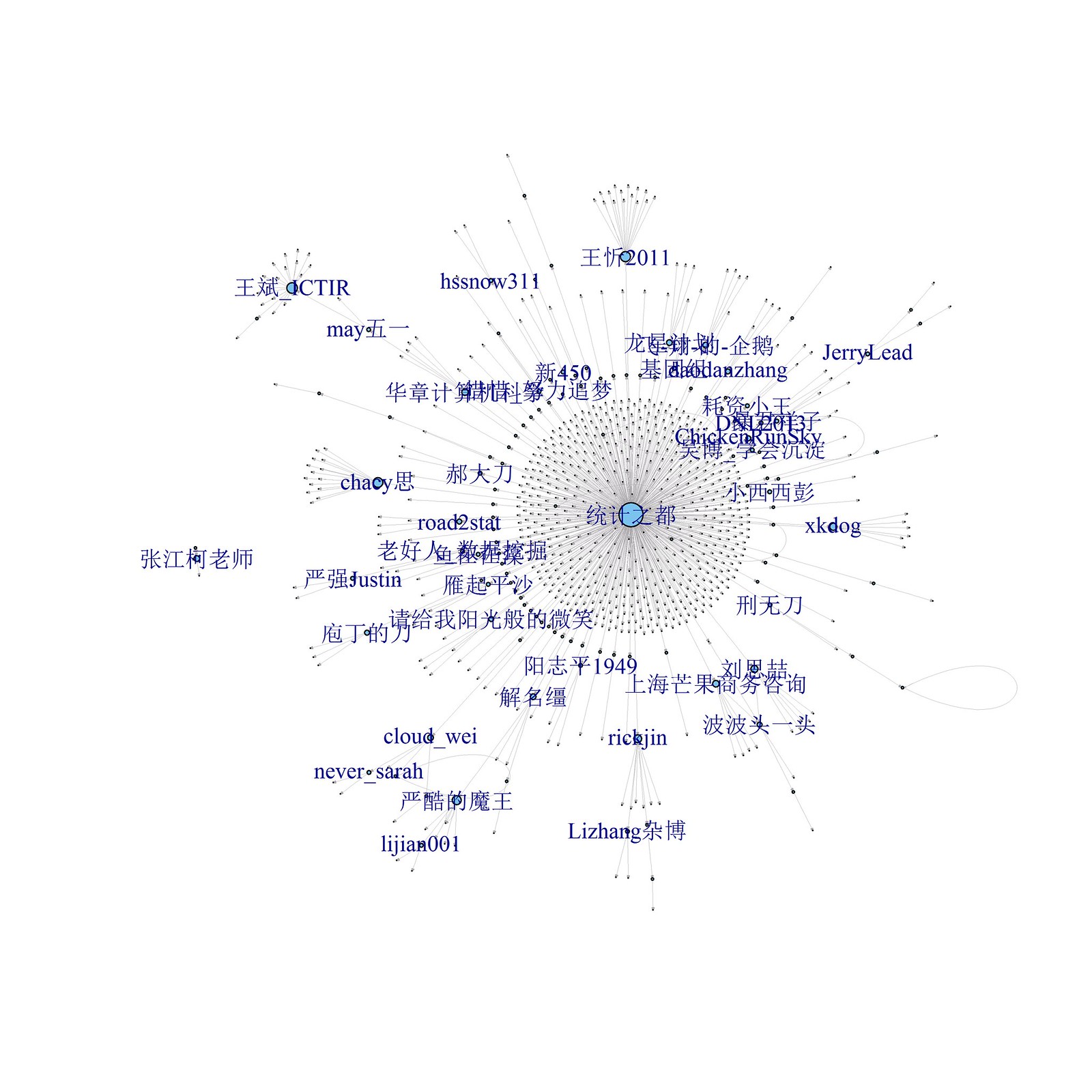
图 11-3. 微博转发网络
# 绘制二度转发网络(剔除了第一步转发)
g1<-graph.data.frame(dat1)
l1<-layout.fruchterman.reingold(g1)
# 明确节点属性
vertex<-as.numeric(V(g1)$name)
V(g1)$size = degree(g1, v=V(g1), mode = c("out"))
nodeName = unique(ana1[,c("User_idstr", "User_screen_name")])
node = as.data.frame(V(g1)$name)
names(node) = c("User_idstr")
nodeLabel = merge(node, nodeName, by = "User_idstr", sort = F, all = FALSE)
nodeLabel$nodeSize = V(g1)$size
nodeLabel$User_screen_name[log(nodeLabel$nodeSize+1) < 1]=""
nodeLabel = nodeLabel$User_screen_name
# 保存图片格式
png("d:/repostGraph2step.png",
width=5, height=5,
units="in", res=700)
# 绘制图片
plot(g1, vertex.label= NA,edge.arrow.size=0.02,vertex.size = 0.5,
layout=l1 )
# 结束保存图片
dev.off()
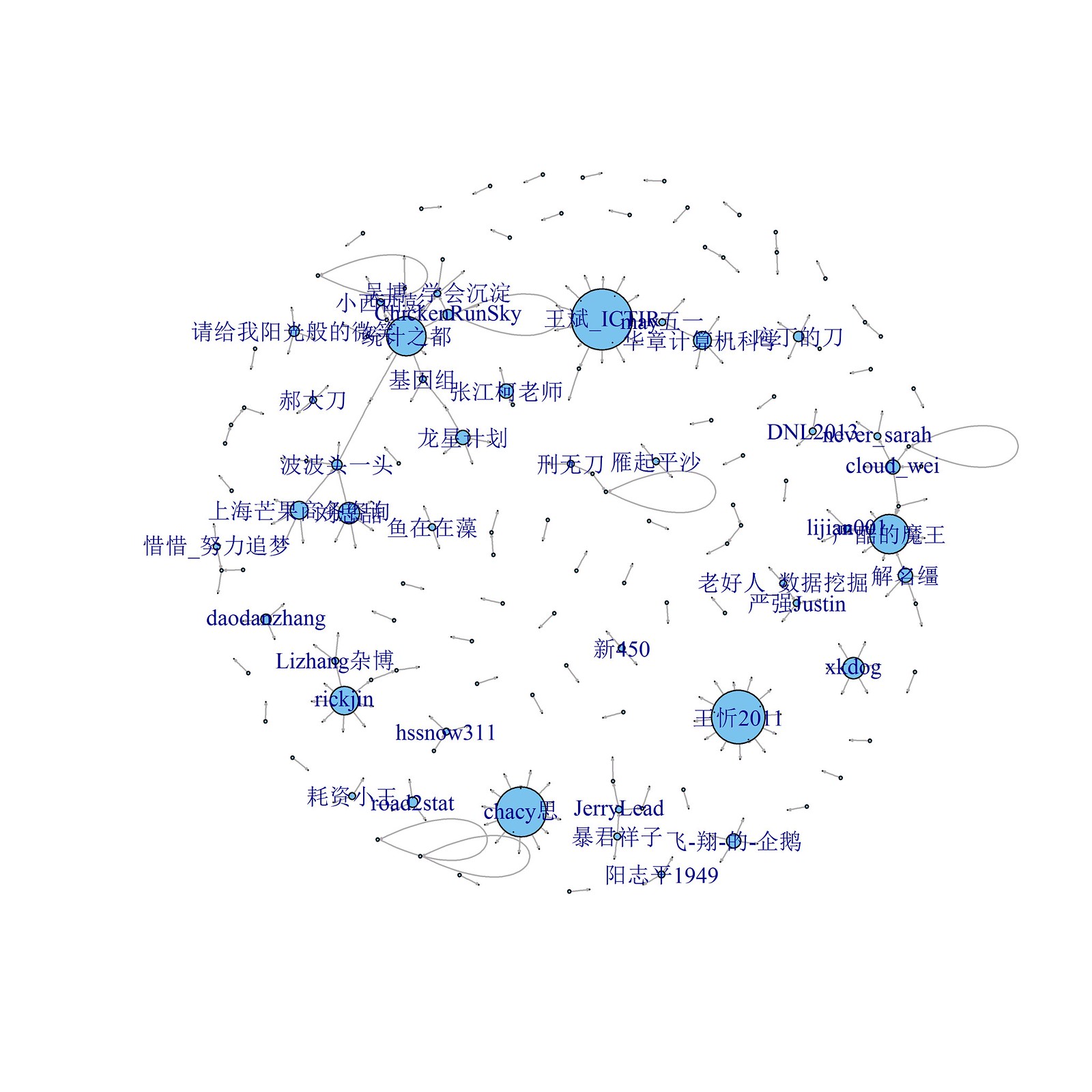
图 11-4. 微博二度转发网络(剔除了第一步转发)
当然,我们还可以通过解析微博内容的方法来提取转发网络。这需要我们对转发微博的内容进行分析,提取其中“//@”后出现的微博用户名。我们借助gsubfn这个R包中的strapply来实现这个过程。
# R程序11-7:通过解析微博内容提取转发网络
library(gsubfn)
findSource = function(n){
res1=strapply(ana1$text[n], paste("\\w*", "//@", "\\w*", sep = ""), c, simplify = unlist)
res2 = ifelse(is.null(res1) == TRUE, 0,unlist(strsplit(res1[1], "@"))[2] )
return(res2)
}
source = unlist(lapply(c(1:length(ana1$text)), findSource))
dat4 = as.data.frame(cbind(source, ana1$User_screen_name)) # 总的转发网络
dat4$source[as.character(dat4$source) == "0"] = "统计之都"
dat5 = subset(dat4, dat4$source != "统计之都") # 二度转发网络
# 绘制总的转发网络
library(igraph)
g4<-graph.data.frame(dat4)
l<-layout.fruchterman.reingold(g4)
plot(g4, vertex.label= NA,edge.arrow.size=0.02,vertex.size = 0.5,
layout=l )
# 绘制二度转发网络
library(igraph)
g5<-graph.data.frame(dat5)
l<-layout.fruchterman.reingold(g5)
plot(g5, vertex.label= NA,edge.arrow.size=0.02,vertex.size = 0.5,
layout=l )
这种直接使用编程语言上手的方法符合“通过实践学习”(learning by doing)的哲学。为社会科学研究者和广大的读者提供了一个轻巧的入门的道路。遇到问题,解决问题,学习者也可以在实际的练习当中进步。当然,千言万语不如付诸行动。只有开始了第一步的下载和安装python,安装一些包,写出第一个有用的程序的时候,才算真正不虚此行。最具有吸引力的是一通百通,会从Twitter上获取信息,你也就具有了从其他网站(如新浪微博)上获取信息的能力。当你走完这一步,我们可以相信,一个可计算的社会科学研究就从你自己这里开始起步了。
三、重新认识网络:一个整体的视角
网络科学(network science)是可计算性社会科学(computational social science)的一个重要组成部分。它不仅提供了一个崭新的视角,还为社会科学提供了一系列的理论和方法。网络科学提供了新的认识社会的视角,即对关系进行计算。通过对关系进行计算,网络科学丰富了人类认识世界的维度。网络无时无刻不存在于我们生活的每个细节:我们生活在一个社会网络当中,没有人是绝对孤立的点,每个个体时刻都在与其他人进行着互动;我们生活的大自然有一个食物网络,能量沿着食物网当中的链接由植物向高级的动物流动;我们的生活处于一个物流网络当中,交通干线承担着人口迁移和物质供给的职能,世界贸易网络刻画着国家间的贸易往来和经济依赖关系,等等。
这种网络的链接有时候充当渠道的作用,网络的流可以藉此得以流通。这种网络当中的流可以具有多种表现形式:信息、商品,货币、信任、命令等。这些网络的流,往往充当着稀缺的社会资源的角色,具有明确而重要的社会功能。网络渠道对于网络的流具有引导和塑形的作用。比如,我们在日常生活中主动地建立自己的社会联系。有时候我们只能观察到其中之一,或者是网络渠道,或者是网络中流,因而链接预测(link prediction)成为网络科学研究当中一个重要议题(Lü & Zhou, 2011)。
把握和认识这种关系能够为我们带来洞察,发现隐藏在事物表象下的模式。关系以链接的形式呈现于网络当中。例如,中国乡土社会当中的人和人之间的关系可以通过新年拜年的网络链接展现,通过观察礼物的类别、价格以及送礼人所使用的语言,我们可以对这种关系进行测量。类似的,恐怖分子通过隐秘的互动网络进行组织,通过观察其互动的频次、方向和时间,我们可以对互动双方的职能进行划分,进而发现其中的等级关系。这种对于网络当中链接所隐含的信息的应用非常普遍。例如,警察破案,很关键的一点是理清犯罪嫌疑人的人际关系网络。在模式的基础上,网络科学家开始更深入地探索网络科学中的法则,例如复杂网络的幂律分布。事实上,此时我们开始触及之前章节关于图论的知识,尤其是关于复杂网络的研究。最简单的网络是规则网,最混沌的网络在随机网。而复杂网络(包括社会网络)则处于从规则走向混沌的过渡阶段。Watts和Strogatz的研究表明将规则网络中的链接(按照一定的概率)随机重连就可以得到小世界网络(Watts & Strogatz, 1998)。Barabási和Albert随后的研究表明复杂网络中节点的度分布具有无标度特征(Barabási & Albert, 1999)。其后,一系列关于复杂网络的小世界特征和无标度性进行推动了网络科学的发展。从网络链接当中找到统一的模式和法则是认识网络的第一步,接下来需要理解网络链接的形成机制。
网络链接的形成机制非常多样:1. 网络节点的流行程度(popularity)如社会影响力(social influence)(Barabási & Albert, 1999; Goodreau SM, 2009; Papadopoulos, Kitsak, Serrano, Boguná, & Krioukov, 2012)、2. 相似性(similarity)或同质性(homophily)(Goodreau SM, 2009; McPherson, Smith-Lovin, & Cook, 2001)、4. 地理空间接近性和社会接近性(spatial and social proximity)(Crandall et al., 2010; Rivera, Soderstrom, & Uzzi, 2010). 当然,除此之外还有很多其它的影响因素来源于: 5. 网络结构,如结构洞(Structural holes)(Burt, 1992)。尤其应当强调的是,基于社会规范(如社会交换)的互惠性(Reciprocity)在网络的行程中发挥着重要作用,因为基于社会规范,我们总是倾向于投桃报李、彼此合作、互利共赢(Cranmer, Heinrich, & Desmarais, 2013);类似的,社会个体倾向于维持认知平衡并避免冲突关系(Davis, 1963; Newcomb, 1953),因而关系的传递性(Transitivity)同样起着重要的作用。例如,在社会网络当中,人们倾向于和朋友的朋友建立网络关系(Goodreau SM, 2009)。
四、QAP检验:两个网络之间的关联
通常一组个体具有多种类型的关系,例如友谊关系和经济往来关系。我们通常会对这两种网络关系在多大程度上相互关联感兴趣。当我们知道一组个体之间的两种关系网络,我们就可以计算这个两个关系网络之间的相关程度。在统计学当中,皮尔森相关系数是用来反映两个变量线性相关程度的统计量。与之类似,对于由一组个体所组成的两个网络,也可以计算其相应的相关皮尔逊相关系数。当然,还可以计算其他你感兴趣的统计量,如协相关系数。
我们使用sna这个R软件包来计算网络相关系数(并调用qaptest命令)。通过安装和使用statnet这个R软件包,就会自动加载sna等子软件包。另外,statnet当中还集成了其他的几个相关的R软件包,包括进行动态网络建模的tergm子软件包。
# R程序11-8:计算网络的皮尔逊相关系数
install.packages("statnet")
library(statnet)
# 首先随机生成3个由10个节点构成的有向网络
g = array(dim=c(3,10,10))
g[1,,] = rgraph(10)
g[2,,] = rgraph(10,tprob=g[1,,]*0.8) # 设置g1和g2两个网络强相关
g[3,,] = 1; g[3,1,2] = 0 # g3接近于一个派系(clique)
# 绘制这3个网络
par(mfrow=c(1,3))
for(i in 1:3) {
gplot(g[i,,],usecurv=TRUE, mode = "fruchtermanreingold",
vertex.sides=3:8)}
#计算网络的相关矩阵
gcor(g)
在通常使用皮尔逊相关系数的时候,可以用t统计量对总体相关系数为0的原假设进行检验。但在计算网络的相关系数(graph correlations)时,经典的零假设检验方法往往会带来偏差,因而并不适用。通常使用非参数检验的方法,比如QAP(Quadratic Assignment Procedure)检验。
矩阵的随机排列(Random matrix permutations)是QAP检验的关键部分,在子软件包sna中主要通过rmperm来进行。通过矩阵的随机排列,可以对网络中的节点(的编号)进行随机置换(relabelling),并得到一组(比如1000个)重连后的网络。
# R程序11-9:矩阵的随机置换方法
j = rgraph(5) # 随机生成一个网络
j #看一下这个网络的矩阵形式
rmperm(j) #随机置换后的网络的矩阵形式
对这一组重构的网络可以计算其网络级别的参数(如两个网络的相关参数,协相关参数),并因此得到一个参数分布。QAP检验的零假设是实际观测到的网络参数(如)来自于这一个参数分布。也就是说,原假设认为这种观测到的相关关系是由随机因素带来的,因而这种网络相关并不显著。拒绝原假设,就从统计的角度证明了观测到的网络相关系数是显著的。
# R程序11-10:QAP检验
q.12 = qaptest(g, gcor, g1 = 1, g2 = 2)
q.13 = qaptest(g, gcor, g1 = 1, g2 = 3)
# 看一下QAP输出的结果
par(mfrow=c(1,2))
summary(q.12)
plot(q.12)
# 拒绝原假设,图1和图2显著相关
summary(q.13)
plot(q.13)
# 接受原假设,图1和图3不相关
在检验这个关于两个网络是否存在相关的零假设的时候,我们计算置换后的参数分布中大于这个实际观测到的参数的比例,以及小于这个实际观测到的参数的比例。QAP检验返回实际数据中观测到的参数f(d)、通过置换所得到的参数f(perm)的数学分布、以及单尾的P值。其中单尾的p值包括两种情况:p(f(perm) >= f(d))和p(f(perm) <= f(d))。
其中P(f(perm) >= f(d))表示随机置换矩阵的相关系数的大于与等于观测值的p值,也就是本研究的检验显著性。一般而言,当p(f(perm) >= f(d))小于p(f(perm) <= f(d))时,拒绝原假设。
思考另外一个问题:如果两个节点之间存在一种关系(例如A和B之间存在相互关注的的朋友关系),是否暗示着他们之间是否可能存在另一种关系(例如A和B之间存在相互转发信息的传播关系)?这样,我们试图去找到一种关系对于另一种关系的影响。例如,两个作者来自同一所学校对于他们之间的合作关系是否具有显著的影响。除此之外,还有节点的属性的影响,网络规模的影响,网络中二元组和三元组的影响等等。指数随机图模型作为一个网络统计模型可以较好地综合不同层级的影响因素,因为成为统计网络数据分析的主要模型。
五、指数随机图模型
指数随机图模型(exponential random graph models, ERGMs)是一种使用蒙特卡罗最大似然(MCMC)方法的logit模型(Frank & Strauss, 1986; Goodreau SM, 2009; Wasserman & Pattison, 1996)。指数随机图模型的因变量是两个节点之间形成链接(tie-formation)的概率。采用马尔科夫链蒙特卡洛(Markov chain Monte Carlo, MCMC)方法,指数随机图模型挑选可以最大化得生成实际观察到的网络的模型(Snijders, 2002)。
定义$\mathbf{Y}$为网络中所有可能的链接关系,$\mathbf{y}$是网络节点间(实际存在或可观察到的)一种具体的链接关系。定义$\mathbf{X}$为网络节点属性,它是一个矩阵。在以上定义基础上,定义$g(\mathbf{y}, \mathbf{X})$为网络的统计量,它是一个向量。这些网络统计量包括两部分:一部分是网络结构的统计量,如链接的数量、二元组数量、三元组数量等;另一部分是网络节点属性的统计量,例如在微博信息转发网络中,网络节点属性包括微博转发者的年龄、性别、地理位置、活跃性、流行程度等。这些网络统计量构成了指数随机图模型的自变量,根据它们,指数随机图模型预测因变量,即节点之间构成链接的概率。
为了进行模型估计,还需要引入一些参数(parameter)。为此,我们定义$\theta$为网络统计量的系数,它是一个向量。此外,$k(\theta )$是归一化常数,它可以确保模型中各种网络统计量形成链接的概率之和为1。这样,关于观察到一组网络链接的概率可以用指数随机模型表示为以下公式:
\[P(\mathbf{Y} = \mathbf{y}|\mathbf{X}) = exp[{\theta } ^{T} g(\mathbf{y},\mathbf{X})]/k(\theta )\]以上模型还可以表达为logit模型的形式。如果两个节点i和j之间存在链接的概率表示为$p_{ij}$,那么不存在链接的概率可以表示为$1-p_{ij}$。$p_{ij} / (1-p_{ij})$表示事件发生的相对似然率(the relative likelihood),又被称之为优势比(odds ratio)。比如,在信息转发的情境当中,A总共发了10条信息,B转发了其中的8条,那么优势比就是0.8/0.2 = 4。Logit模型当中的因变量是优势比的自然对数形式,相应的模型表达为以下形式:
\[logit(Y_{ij} = 1) = ln(\frac{p_{ij}}{1-p_{ij}}) = {\theta }^{T} \mathbf{\delta} [g(\mathbf{y}, \mathbf{X})]_{ij}\]以上公式当中,定义$Y_{ij}$为节点i和j之间形成链接的一个随机变量。当$y_{ij}$取值由0变为1的时候,所带来的$g(\mathbf{y},\mathbf{X})$的变化表示为$\mathbf{\delta} [g(\mathbf{y}, \mathbf{X})]_{ij}$。
statnet是一个R包 (Goodreau, Handcock, Hunter, Butts, & Morris, 2008),其中包含了三个子包:network, sna, 和ergm。本部分我们主要使用network来建立网络对象,并使用ergm针对网络对象建立指数随机图模型。
使用network子包建立网络模型主要是将边的列表或者邻接矩阵的数据转化为statnet所默认的网络对象形式。例如,在以下程序中,我们将所抓取的微博转发网络数据转化为网络对象形式。
#R程序 11-11:建立微博转发网络的ERG模型
library("statnet")
# memory.limit(2000) #设置R调用内存的上限2GB
# 将数值类型的变量转化为字符类型的变量以避免"vector size specified is too large"
dat3[,1] = as.character(dat3[,1])
dat3[,2] = as.character(dat3[,2])
# 将edgelist类型的数据转化为一个网络对象
n = network(dat3, vertex.attr=NULL, vertex.attrnames=NULL, matrix.type="edgelist", directed=TRUE)
summary(n) # 看一下网络的基本信息
指数随机图模型的一个优势是可以综合不同层级的影响因素(比如节点属性,链接或二元组属性、三元组属性、网络规模属性),其中的之一就是将网络节点属性纳入分析。其中的一个容易被忽略的关键点是将网络对象中的节点与原数据对应起来。
此处,我们首先要明确网络对象中的节点(通过以下程序中的network.vertex.name来获取)并得到一个列数为1的网络节点数据。然后,我们将原始数据中的节点属性并入到网络节点数据中(通过merge命令来合并数据)。特别注意是此处推荐使用plyr包里面的join命令,因为在使用merge命令来合并数据的时候,即使设置“sort = F”其排序依然会出问题。最后,采用set.vertex.attribute命令就可以对节点属性进行设定。
# 网络对象中的节点
node = data.frame(network.vertex.names(n), stringsAsFactors = F)
names(node) = c("User_idstr")
# 选取纳入分析的节点属性
att = unique(ana1[,c("User_idstr",
"User_screen_name", "User_gender",
"User_followers_count", "User_friends_count",
"User_statuses_count", "User_verified" )])
# 合并节点属性到网络节点数据
# Add province name
province = read.csv("D:/chengjun/css/part05/chapter11/data/weiboprovince.csv",
stringsAsFactors= F, header = F, sep = ",")
names(province) = c("User_province", "User_province_name")
library(plyr)
att1 = join(att, province, by = "User_province" )
nodeAtt = join(node, att, by = "User_idstr")
set.vertex.attribute(n,"User_gender",nodeAtt$User_gender)
nodeAtt$User_verified[is.na(nodeAtt$User_verified)]="FALSE"
set.vertex.attribute(n,"User_verified",nodeAtt$User_verified)
nodeAtt$User_friends[is.na(nodeAtt$User_friends)]=0
set.vertex.attribute(n,"User_friends",nodeAtt$User_friends)
set.vertex.attribute(n,"User_city",nodeAtt$User_city)
set.vertex.attribute(n,"User_province",nodeAtt$User_province)
set.vertex.attribute(n,"User_bi_followers",nodeAtt$User_bi_followers_count)
nodeAtt$User_followers_count[is.na(nodeAtt$User_followers_count)]=0
set.vertex.attribute(n,"User_followers",nodeAtt$User_followers_count)
set.vertex.attribute(n,"User_statuses",nodeAtt$User_statuses_count)
set.vertex.attribute(n,"User_favourites",nodeAtt$User_favourites_count)
当数据的准备工作做好之后,这个时候我们可以重新查看网络对象(在我们的饿例子中是n)的属性。在R console当中,输入summary(n)即可查看网络属性:
Network attributes:
vertices = 870
directed = TRUE
hyper = FALSE
loops = FALSE
multiple = FALSE
bipartite = FALSE
total edges= 890
missing edges= 0
non-missing edges= 890
density = 0.001177202
Vertex attribute names:
User_followers User_friends User_gender User_statuses User_verified vertex.names
此时,我们就可以正式开始模型设定和参数估计。这里,我们首先建立一个最为简单的网络模型m0。m0仅仅考虑最简单的网络参数,即网络当中的链接的数量。模型m0假设网络中的链接是随机生成的,也就是Erdős Rényi 随机网络模型(random graph)的基本要求,因而这个模型所生成的网络必然具备随机网络模型的特点(Erdős & Rényi, 1959)。
# ERG模型的模型设定(Model Specification)
m0<-ergm(n ~ edges, parallel=10)
summary(m0)
==========================
Summary of model fit
==========================
Formula: n ~ edges
Iterations: 20
Monte Carlo MLE Results:
Estimate Std. Error MCMC % p-value
edges -6.75703 0.03377 NA <1e-04 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Null Deviance: 1048080 on 756030 degrees of freedom
Residual Deviance: 13622 on 756029 degrees of freedom
AIC: 13624 BIC: 13636 (Smaller is better.)
该模型结果表明按照随机网络模型生成的网络,其中每一个网络链接(即信息转发)的log-odds是$-6.75703\mathbf{\delta} [g(\mathbf{y},\mathbf{X})]{ij}$。因为每增加任意一个链接,本模型的网络统计量(也就是网络中的链接的数量)增加1,所以$\mathbf{\delta} [g(\mathbf{y}, \mathbf{X})]{ij}$等于1。所以生成每条网络链接的对数优势比就是-6.75703。由此,不难算出生成每条网络链接的概率为exp(-6.75703)/(exp(-6.75703) + 1) = 0.001161327,而这个数值与实际的信息转发网络(有向)的网络密度(density)0.001177202非常接近。
除了零模型中的边数之外,指数随机图模型还可以控制其它网络结构的因素,如网络中的的二元组的数量(通过mutual来在ergm中设定)和三元组的数量(通过gwesp在ergm中设定)。
另外,指数随机图模型可以很容易的分析节点属性对于网络中的链接形成的影响,主要分析两种网络构成机制:流行性(popularity)和相似性(similarity)(Papadopoulos, et al., 2012)。首先,流行性主要分析一个节点的某种流行性的属性,比如一个信息转发者的粉丝的数量,在指数随机图模型中主要通过nodefactor和nodecov来设定。nodefactor主要分析针对的是类别变量,如性别、籍贯等;而nodecov主要针对的是连续型变量,如年龄、收入等。在有向网络当中,根据节点的入度和出度的区分,nodefactor和nodecov又可以区分为nodeicov和nodeocov,以及nodeifactor和nodeofactor。其次,相似性主要强调的是网络节点的两两之间在某种属性上的相似程度,在statnet的ergm命令当中主要通过nodematch来设定。如果说nodefactor和nodecov测量的是节点属性的主效应(main effect)的话,那么nodematch测量的主要是节点属性在网络链接水平上的匹配程度,也可以理解为交互效应。
举一个例子来理解流行性和相似性作为两种一般性的影响因素在指数随机图模型当中的刻画,读者可以参阅 Goodreau (2009)关于青少年个体属性(性别、种族、年级)对于社会网络构成的影响。Goodreau认为个体属性的主要效应在友谊形成网络当中主要可以区分为两类:社交性(sociality)和同质性(homophily)。其中前者对应于流行性,而后者对应于相似性。与之相应,在指数随机图模型的设定当中,前者通过nodefactor/nodecov测量,而后者主要通过nodematch测量。
# ERG Model Specification
m0<-ergm(n ~ edges + nodematch("User_province")
+ mutual + gwesp(fixed=T, cutoff=30), parallel=10)
summary(m0)
mcmc.diagnostics(m0)
模型的运行结果如下:
Estimate Std. Error MCMC % p-value
edges -6.93374 0.03907 0 <1e-04 ***
nodematch.User_province 0.95514 0.07629 0 <1e-04 ***
mutual 0.42916 1.00405 0 0.669
gwesp.fixed.0 0.56772 0.72052 0 0.431
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Null Deviance: 1048080 on 756030 degrees of freedom
Residual Deviance: 13498 on 756026 degrees of freedom
AIC: 13506 BIC: 13552 (Smaller is better.)
mcmc.diagnostics(m0)
当然了,我们可以根据研究目的建立更加完整的网络模型。例如,在以下的模型m1当中,我们开始考虑朋友数量、粉丝数量、用户性别、用户级别(是否认证用户)对于网络模型中链接形成的影响。需要注意的是该模型的运行时间很长,读者需要耐心等待。
m1<-ergm(n ~ edges + nodecov("User_friends")+ nodecov("User_followers")
+ nodematch("User_province") + nodefactor("User_province")
+ nodematch("User_gender")+ nodematch("User_verified")
+ mutual + gwesp(fixed=T, cutoff=30), parallel=10)
summary(m1)
mcmc.diagnostics(m1)
模型的运行结果如下:
# ==========================
# Summary of model fit
# ==========================
#
# Formula: n ~ edges + nodecov("User_friends") + nodecov("User_followers") +
# nodematch("User_province") + nodefactor("User_province") +
# nodematch("User_gender") + nodematch("User_verified") + mutual +
# gwesp(fixed = T, cutoff = 30)
#
# Iterations: 20
#
# Monte Carlo MLE Results:
# Estimate Std. Error MCMC % p-value
# edges -1.716e+01 3.984e-01 0 < 1e-04 ***
# nodecov.User_friends -1.626e-03 1.846e-04 0 < 1e-04 ***
# nodecov.User_followers 5.482e-04 1.216e-05 0 < 1e-04 ***
# nodematch.User_province 3.831e-01 1.835e-01 0 0.036892 *
# nodefactor.User_province.12 2.132e-01 3.502e-01 0 0.542661
# nodefactor.User_province.13 -7.425e-01 6.034e-01 0 0.218500
# nodefactor.User_province.14 -8.294e-01 1.031e+00 0 0.421116
# nodefactor.User_province.15 -5.463e-01 1.254e+00 0 0.663011
# nodefactor.User_province.21 -7.493e-01 5.439e-01 0 0.168295
# nodefactor.User_province.22 8.519e-02 3.643e-01 0 0.815101
# nodefactor.User_province.23 -2.727e-01 3.946e-01 0 0.489453
# nodefactor.User_province.31 -3.235e-01 1.719e-01 0 0.059810 .
# nodefactor.User_province.32 -1.399e-01 2.522e-01 0 0.579093
# nodefactor.User_province.33 -1.466e-01 2.267e-01 0 0.517730
# nodefactor.User_province.34 -2.558e-01 4.437e-01 0 0.564221
# nodefactor.User_province.35 -4.032e-01 3.437e-01 0 0.240691
# nodefactor.User_province.36 3.205e-01 5.578e-01 0 0.565517
# nodefactor.User_province.37 -1.294e-01 4.125e-01 0 0.753818
# nodefactor.User_province.41 -3.616e-01 4.546e-01 0 0.426427
# nodefactor.User_province.42 -3.622e-01 3.374e-01 0 0.283047
# nodefactor.User_province.43 -3.551e-01 4.317e-01 0 0.410737
# nodefactor.User_province.44 -6.743e-02 1.567e-01 0 0.667042
# nodefactor.User_province.45 1.205e-01 1.106e+00 0 0.913280
# nodefactor.User_province.46 -2.464e-01 9.628e-01 0 0.798021
# nodefactor.User_province.50 -4.050e-01 5.908e-01 0 0.492984
# nodefactor.User_province.51 -6.097e-01 3.412e-01 0 0.074006 .
# nodefactor.User_province.52 -3.054e-01 7.901e-01 0 0.699042
# nodefactor.User_province.53 3.954e-01 5.112e-01 0 0.439207
# nodefactor.User_province.61 -9.135e-02 4.958e-01 0 0.853833
# nodefactor.User_province.62 -7.939e-01 1.505e+00 0 0.597808
# nodefactor.User_province.64 -1.170e-01 1.641e+00 0 0.943158
# nodefactor.User_province.71 2.458e+00 1.607e+00 0 0.126091
# nodefactor.User_province.81 2.587e-03 4.796e-01 0 0.995696
# nodefactor.User_province.100 3.966e-01 1.915e-01 0 0.038304 *
# nodefactor.User_province.400 -4.561e-01 2.430e-01 0 0.060461 .
# nodematch.User_gender 5.707e-01 1.598e-01 0 0.000355 ***
# nodematch.User_verified 9.986e+00 3.039e-01 0 < 1e-04 ***
# mutual -8.400e+00 2.566e+00 0 0.001063 **
# gwesp.fixed.0 -4.064e+00 8.897e-01 0 < 1e-04 ***
# ---
# Signif. codes: 0 ?**?0.001 ?*?0.01 ??0.05 ??0.1 ??1
#
# Null Deviance: 1048080 on 756030 degrees of freedom
# Residual Deviance: 7680 on 755991 degrees of freedom
#
# AIC: 7758 BIC: 8208 (Smaller is better.)
六、讨论和结论
本章以网络科学为核心,勾勒了科学与可计算性的关系,描绘了数字化媒体和大数据的广泛应用,在此基础上重新思考了网络科学所蕴含的意义,并结合实际的案例介绍统计学方法在网络科学当中的应用。
应当注意的是,本文只是一个基础的引论,而非全面而严格的介绍。本文的意义在于启发读者和勾勒大的图景。限于篇幅,对于很多具体的数学细节和理论问题并没有足够的论述。读者需要根据本文的参考文献按图索骥。通过进一步的阅读和学习来加深对网络科学的理解,并根据自己的需要在实践当中学习。
参考文献
Barabási, A.-L., & Albert, R. (1999). Emergence of scaling in random networks. science, 286(5439), 509-512.
Barabasi, A.-L. (2003). Linked: How everything is connected to everything else and what it means for business, science, and everyday life. New York: Plume.
Burt, R. S. (1992). Structural holes. Boston: Harvard University Press.
Crandall, D. J., Backstrom, L., Cosley, D., Suri, S., Huttenlocher, D., & Kleinberg, J. (2010). Inferring social ties from geographic coincidences. Proceedings of the National Academy of Sciences, 107(52), 22436-22441.
Cranmer, S. J., Heinrich, T., & Desmarais, B. A. (2013). Reciprocity and the structural determinants of the international sanctions network. Social Networks, http://www.sciencedirect.com/science/article/pii/S0378873313000026.
Davis, J. A. (1963). Structural balance, mechanical solidarity, and interpersonal relations. American Journal of Sociology, 68, 444-462.
Erdős, P., & Rényi, A. (1959). On random graphs. Publicationes Mathematicae Debrecen, 6, 290-297.
Frank, O., & Strauss, D. (1986). Markov graphs. Journal of the american Statistical association, 81(395), 832-842.
Goodreau, S. M., Handcock, M. S., Hunter, D. R., Butts, C. T., & Morris, M. (2008). A statnet tutorial. Journal of statistical software, 24(9), 1-26.
Goodreau SM, K. J., Morris M (2009). Birds of a feather, or friend of a friend? Using exponential random graph models to investigate adolescent social networks. Demography, 46, 103-125.
Lü, L., & Zhou, T. (2011). Link prediction in complex networks: A survey. Physica A: Statistical Mechanics and its Applications, 390(6), 1150-1170.
Lazer, D., & Pentland, A. S., Adamic, Lada., Aral, Sinan., Barabasi, Albert Laszlo., Brewer, Devon., Christakis, Nicholas., Contractor, Noshir., Fowler, James., Gutmann, Myron. (2009). Life in the network: The coming age of computational social science. Science, 323(5915), 721.
Li, J. (2013). Rweibo: An interface to the Weibo open platform. http://jliblog.com/app/rweibo.
McPherson, M., Smith-Lovin, L., & Cook, J. M. (2001). Birds of a feather: Homophily in social networks. Annual review of sociology, 27, 415-444.
Newcomb, T. M. (1953). An approach to the study of communicative acts. Psychological review, 60(6), 393.
Papadopoulos, F., Kitsak, M., Serrano, M. Á., Boguná, M., & Krioukov, D. (2012). Popularity versus similarity in growing networks. Nature, 489(7417), 537-540.
Rivera, M. T., Soderstrom, S. B., & Uzzi, B. (2010). Dynamics of dyads in social networks: Assortative, relational, and proximity mechanisms. Annual review of sociology, 36, 91-115.
Russell, M. A. (2011). Mining the social web: Analyzing data from Facebook, Twitter, LinkedIn, and other social media sites. Cambridge: O’Reilly.
Snijders, T. A. (2002). Markov chain Monte Carlo estimation of exponential random graph models. Journal of Social Structure, 3(2), 1-40.
Wasserman, S., & Pattison, P. (1996). Logit models and logistic regressions for social networks: I. An introduction to Markov graphs and p*. Psychometrika, 61(3), 401-425.
Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ‘small-world’networks. Nature, 393(6684), 440-442.
Wing, J. M. (2006). Computational thinking. Communications of the ACM, 49(3), 33-35. 吴军. (2012). 数学之美. 北京: 人民邮电出版社.



Leave a Comment