
真实熵与人类行为可预测性
在Limits of Predictability in Human Mobility一文(Song, 2010, Science)当中,Song等人提出人类移动行为的可预测性问题。强调了采用香农熵或随机熵不能捕捉到移动位置的时间序列特点,主张采用一种真实熵(the actual entropy)的测量方式,表示为S; 以一个小时为一个观察窗口,观察一段连续的时间里的人类个体移动轨迹,一个人到过的地点总数是N。
计算真实熵的方法是采用一种称之为Lempel-Ziv的算法来进行估计。
\[E= (\frac{1}{n} \sum_i \Lambda_i )^{-1} ln (n)\]where $\Lambda_i$ is the length of the shortest substring starting at position i which doesn’t previously appear from position 1 to i-1.
The estimated entropy converges to the real entropy of the time series when n approaches to infinity.1
def contains(small, big):
for i in range(len(big)-len(small)+1):
if big[i:i+len(small)] == small:
return True
return False
def actual_entropy(l):
n = len(l)
sequence = [l[0]]
sum_gamma = 0
for i in range(1, n):
for j in range(i+1, n+1):
s = l[i:j]
if not contains(list(s), sequence): # s is not contained in previous sequence
sum_gamma += len(s)
sequence.append(l[i])
break
ae = 1 / (sum_gamma / n ) * math.log(n)
return ae
但是这个算法的计算复杂度比较高,对于观察窗口为秒或者毫秒的长时间序列,很难算出来。一开始我们在stackover flow上提了这个问题。后来才发现Song也是按照小时为观察窗口计算的!
To construct a time series for each user we segment the three month observation period into hour-long intervals. Each interval is assigned a tower ID if one is known (i.e. the phone was used in that time interval). If multiple calls were made in a given interval, we choose one of them at random. Finally if no call is made in a given interval, we assign it an ID “?”, implying an unknown location. Thus for each user i we obtain a string of length $L = 24 * 7 * 14 = 2352$ with $N_i + 1$ distinct symbols, each denoting one of the Ni towers visited by the user and one for the missing location “?”. (Supporting Online Material for Limits of Predictability in Human Mobility, page 4)
基于这种思路,就可以计算出来任何一个时间序列的真实熵。
%matplotlib inline
import numpy as np
import pylab as pl
import pandas as pd
使用mpmath来计算可预测性
算出来了真实熵,仅仅把握住了可预测性的一个因素。可预测性与不确定性之间成反比,但也与观察到的地点数量N有关系!根据Song的思路,他们按照Fano’s inequality来表示可预测性。
That is, if a user with entropy $S$ moves between $N$ locations, then her or his predictability $P \leqslant P_{max}(S,N)$, where $P_{max}$ is given by
\[S = H(P_{max}) + (1 - P_{max}) log2(N -1)\]with the binary entropy function $H(P_{max}) = - P_{max} log2(P_{max}) - (1 - P_{max}) log2(1 - P_{max})$.
这样就可以把$P_{max}$表示成N和S两个参数的函数,令$P_{max} = x$,也就可以看成$( \frac{1-x}{N-1}) ^{1-x} x^x - 2^{-S} = 0$的方程。
最初,我们尝试使用sympy来解这个方程,没有成功。
N and S are constants, for example N = 201 and S = 0.5. I use sympy in python to solve it. The python script is given as following:
from sympy import *
x=Symbol('x')
print solve( (((1-x)/200) **(1-x))* x**x - 2**(-0.5), x)
However, there is a RuntimeError: maximum recursion depth exceeded in instancecheck
I have also tried to use Mathematica, and it can output a result of 0.963
http://www.wolframalpha.com/input/?i=(((1-x)%2F200)+(1-x))*+xx+-+2**(-0.5)+%3D+0
在我发起悬赏之后,Izaak van Dongen给出了一个使用mpmath的解决方案:https://stackoverflow.com/questions/46905044/runtimeerror-in-solving-equation-using-sympy/
Mpmath is a Python library for arbitrary-precision floating-point arithmetic. For general information about mpmath, see the project website http://code.google.com/p/mpmath/, 在sympy的网站上也有mpmath的使用手册 http://docs.sympy.org/0.7.6/modules/mpmath/
Specifically, mpmath.findroot seems to do what you want. It takes an actual callable Python object which is the function to find a root of, and a starting value for x.
import mpmath
N = 201
S = 0.5
def getPredictability(N, S):
f = lambda x: (((1-x)/(N-1)) **(1-x))* x**x - 2**(-S)
root = mpmath.findroot(f, 1)
return float(root.real)
getPredictability(N, S)
0.9639047615927534
N = 201
slist = np.arange(0, 1.1 ,0.1)
plist = []
for S in slist:
p = getPredictability(N, S)
plist.append(p)
plist
[1.0,
0.9939185814424049,
0.9869605566060163,
0.9795709141746703,
0.9718658516192474,
0.9639047615927534,
0.955724375464196,
0.9473498380470712,
0.9387994963345618,
0.9300873355592305,
0.9212243585880542]
pl.plot(slist, plist, 'g-o')
pl.xlabel('$S$', fontsize = 20)
pl.ylabel('$\Pi{max}$ ', fontsize = 20)
pl.show()
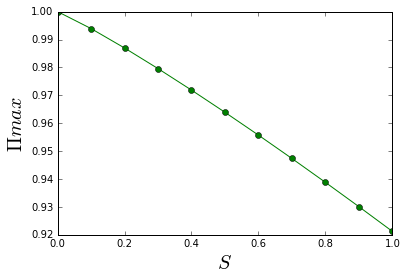
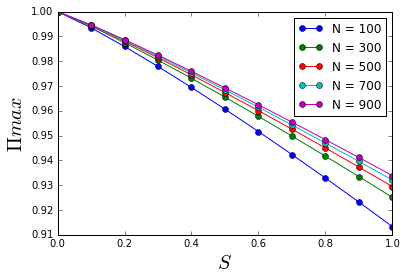
Number of observations, Real Entropy, and Predictability
nlist = np.arange(100, 1000, 200)
slist = np.arange(0, 1.1 ,0.1)
nsplist = []
for N in nlist:
for S in slist:
p = getPredictability(N, S)
nsplist.append([N, S, p])
df = pd.DataFrame(nsplist, columns = ['N', 'S', 'P'])
groups = df.groupby('N')
for name, group in groups:
pl.plot(group.S, group.P, label = "N = "+ str(name), marker='o', linestyle='-')
pl.legend()
pl.xlabel('$S$', fontsize = 20)
pl.ylabel('$\Pi{max}$ ', fontsize = 20)
pl.show()
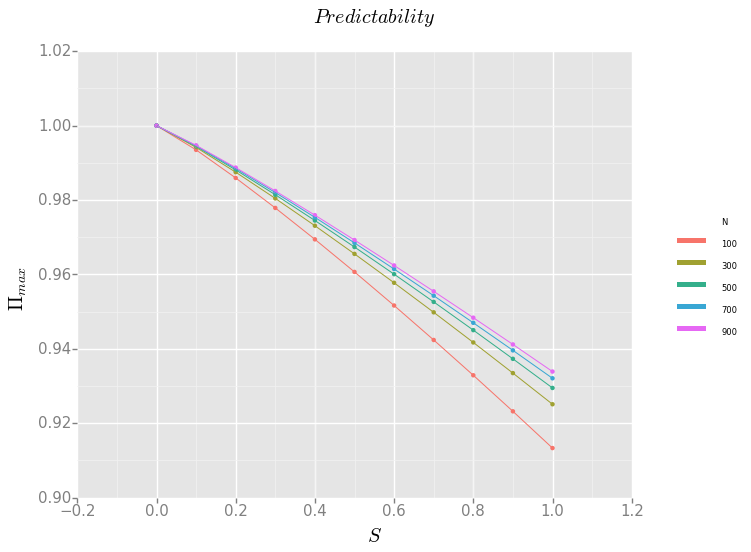
ggplot
from ggplot import *
df['N'] = [str(i) for i in df.N]
#pl.rcParams['figure.figsize'] = (4, 4)
p = ggplot(aes(x='S', y='P', colour= 'N'), data=df) \
+ geom_point() + geom_line()\
+ xlab("$S$") + ylab("$\Pi_{max}$") + ggtitle("$Predictability$")
t = theme_gray()
t._rcParams['font.size'] = 20
t._rcParams['xtick.labelsize'] = 15 # xaxis tick label size
t._rcParams['ytick.labelsize'] = 15 # yaxis tick label size
t._rcParams['axes.labelsize'] = 50 # axis label size
p + t
结论
- 真实熵越大,可预测性越小;
- 在熵不变的条件下,去过的地方越多,可预测性越强。
-
Kontoyiannis I., Algoet P. H., Suhov Yu. M., Wyner A. J. Nonparametric Entropy Estimation for Stationary Processes and Random Fields, with Applications to English Text, IEEE Transactions on Information Theory 44, 1319-1327 (1998). ↩



Leave a Comment