
This tutorial was partially adapted from http://enipedia.tudelft.nl/wiki/OpenRefine_Tutorial, where you can learn more about Open Refine. It used to be called Google Refine so try that too when you are searching for information. However, in our case, we use python to do the same thing.
Downloading Data
The university data can be downloaed from http://enipedia.tudelft.nl/enipedia/images/f/ff/UniversityData.zip
What you can learn
The data contains quite a few issues, and this tutorial shows how to do things like:
- Cleaning up inconsistent spelling of terms (i.e. “USA”, “U.S.A”, “U.S.”, etc).
- Converting values that are text descriptions of numeric values (i.e. $123 million) to actual numeric values (i.e. 123000000) which are usable for analysis.
- Identifying which rows of a specific column contain a search term
- Extracting and cleaning values for dates
- Removing duplicate rows
- Using a scatterplot to visualize relationships between values in different columns
Finding geographic coordinates for a list of place names (i.e. the names of universities, etc.)- Exporting cleaned data to Excel
Reading Data with Pandas
%matplotlib inline
import sys
import pandas as pd
import statsmodels.api as sm
from collections import Counter, defaultdict
import numpy as np
import datetime
import matplotlib.pyplot as plt
import matplotlib
matplotlib.style.use('ggplot')
df = pd.read_csv('universityData.csv', sep = '\t')
df.head()
| university | endowment | numFaculty | numDoctoral | country | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Paris Universitas | 15 | 5500 | 8000 | France | NaN | 2005 | NaN | 25000 | 70000 |
| 1 | Paris Universitas | 15 | 5500 | 8000 | France | NaN | 2005 | NaN | 25000 | 70000 |
| 2 | Lumi%C3%A8re University Lyon 2 | 121 | NaN | 1355 | France | NaN | 1835 | 7046 | 14851 | 27393 |
| 3 | Confederation College | 4700000 | NaN | NaN | Canada | NaN | 1967 | not available | pre-university students; technical | 21160 |
| 4 | Rocky Mountain College | 16586100 | NaN | NaN | United States | NaN | 1878 | 66 | 878 | 894 |
print df.university[2]
Lumi%C3%A8re University Lyon 2
Apparently, there are duplicate rows.
len(df)
75043
Deduplicate entries 1.0
df = df.drop_duplicates()
len(df)
15534
We already see an issue here where there is both the full name of a country (United States) and its abbreviation (US). To fix this, we can just copy/paste “United States” as the new cell value.
Clean up country names
df['country'].unique()
array(['France', 'Canada', 'United States', 'USA', 'Italy', 'South Korea',
'Japan', 'United States of America', 'England, UK',
'United States )', 'Saudi Arabia', 'Honduras', 'United Kingdom',
'England', 'the Netherlands', 'India', 'Russia', 'U.S.', 'Brazil',
'US', 'U.S.A.', 'Philippines', 'Australia',
'England, United Kingdom', 'Wales', ',', 'China', 'South Africa',
'UK', 'Puerto Rico', 'Bulgaria', 'Botswana', 'Taiwan', 'Sri Lanka',
'Colombia', 'Iran', 'Russian Federation', 'Rossija', 'Finland',
'Republic of China', 'Chile', 'Romania', 'Utopia', 'Singapore',
'Lebanon', 'Turkey', 'Canada B1P 6L2', 'Jordan', 'Albania',
'Canada C1A 4P3 Telephone: 902-566-0439 Fax: 902-566-0795',
'Scotland', 'Pakistan', 'Scotland, United Kingdom', 'Denmark',
'Mexico', 'Thailand', 'Argentina', 'Cura%C3%A7ao', 'Sweden',
'Scotland, UK', 'Bangladesh', 'Nepal', 'Netherlands', 'Switzerland',
'Egypt', 'Spain', 'Satellite locations:',
'Nassau, Bahamas Fort Myers, FL Jacksonville, FL Miami, FL Miramar, FL Orlando, FL Palm Beach, FL Tampa, FL'], dtype=object)
country_df = df.groupby('country').size()
for k in country_df.index:
print(k, country_df[k])
(',', 2)
('Albania', 8)
('Argentina', 1)
('Australia', 49)
('Bangladesh', 27)
('Botswana', 1)
('Brazil', 10)
('Bulgaria', 2)
('Canada', 625)
('Canada B1P 6L2', 40)
('Canada C1A 4P3 Telephone: 902-566-0439 Fax: 902-566-0795', 1)
('Chile', 1)
('China', 4)
('Colombia', 1)
('Cura%C3%A7ao', 1)
('Denmark', 8)
('Egypt', 1)
('England', 338)
('England, UK', 286)
('England, United Kingdom', 64)
('Finland', 2)
('France', 8)
('Honduras', 1)
('India', 40)
('Iran', 9)
('Italy', 2)
('Japan', 112)
('Jordan', 2)
('Lebanon', 5)
('Mexico', 2)
('Nassau, Bahamas Fort Myers, FL Jacksonville, FL Miami, FL Miramar, FL Orlando, FL Palm Beach, FL Tampa, FL', 1)
('Nepal', 4)
('Netherlands', 2)
('Pakistan', 2)
('Philippines', 147)
('Puerto Rico', 2)
('Republic of China', 1)
('Romania', 1)
('Rossija', 2)
('Russia', 1)
('Russian Federation', 2)
('Satellite locations:', 1)
('Saudi Arabia', 1)
('Scotland', 64)
('Scotland, UK', 16)
('Scotland, United Kingdom', 16)
('Singapore', 4)
('South Africa', 7)
('South Korea', 7)
('Spain', 1)
('Sri Lanka', 4)
('Sweden', 24)
('Switzerland', 8)
('Taiwan', 1)
('Thailand', 4)
('Turkey', 4)
('U.S.', 304)
('U.S.A.', 81)
('UK', 83)
('US', 455)
('USA', 5104)
('United Kingdom', 405)
('United States', 6949)
('United States )', 1)
('United States of America', 167)
('Utopia', 1)
('Wales', 2)
('the Netherlands', 2)
us_condition = df['country'].isin(['U.S.', 'U.S.A.', 'US', 'United States', 'United States )', 'United States of America'])
df['country'][us_condition] = 'USA'
ca_condition =[]
for i in df['country']:
if i.__contains__('Canada'):
ca_condition.append(True)
else:
ca_condition.append(False)
df['country'][ca_condition] = 'Canada'
ca_condition =[]
for i in df['country']:
if i.__contains__('China'):
ca_condition.append(True)
else:
ca_condition.append(False)
df['country'][ca_condition] = 'China'
ca_condition =[]
for i in df['country']:
if i.__contains__('England'):
ca_condition.append(True)
else:
ca_condition.append(False)
df['country'][ca_condition] = 'England'
ca_condition =[]
for i in df['country']:
if i.__contains__('Scotland'):
ca_condition.append(True)
else:
ca_condition.append(False)
df['country'][ca_condition] = 'England'
uk_condition = df['country'].isin(['UK', 'United Kingdom', 'Wales'])
df['country'][uk_condition] = 'England'
ca_condition =[]
for i in df['country']:
if i.__contains__('Netherlands'):
ca_condition.append(True)
else:
ca_condition.append(False)
df['country'][ca_condition] = 'Netherlands'
ca_condition =[]
for i in df['country']:
if i.__contains__('Russia'):
ca_condition.append(True)
else:
ca_condition.append(False)
df['country'][ca_condition] = 'Russia'
ca_condition =[]
for i in df['country']:
if i.__contains__('Bahamas'):
ca_condition.append(True)
else:
ca_condition.append(False)
df['country'][ca_condition] = 'Bahamas'
'Russian Federation'.__contains__('Russia')
True
uk_condition = df['country']=='Cura%C3%A7ao'
df['country'][uk_condition] = "Curacao"
df[df['country']==',']
| university | endowment | numFaculty | numDoctoral | country | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 2130 | Universidad Ju%C3%A1rez Aut%C3%B3noma de Tabasco | 23760.0 | 2188 | NaN | , | 1087 | 1958-11-20 | 971 | 24921 | 35271 |
| 3077 | Universidad Ju%C3%A1rez Aut%C3%B3noma de Tabasco | 34140.0 | 2188 | NaN | , | 1087 | 1958-11-20 | 971 | 24921 | 35271 |
Universidad Juárez Autónoma de Tabasco is a public institution of higher learning located in Villahermosa, Tabasco, Mexico.
uk_condition = df['country']==','
df['country'][uk_condition] = "Mexico"
df[df['country']=='Satellite locations:']
| university | endowment | numFaculty | numDoctoral | country | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 75009 | Nova Southeastern University | US $64.5 million | 2083 | NaN | Satellite locations: | 4319 | 1964 | 22060 | 6397 | 28457 |
Nova Southeastern University (NSU) is a private nonprofit university, with a main campus located on 300 acres (120 ha) in Davie, in the US state of Florida. Formerly referred to as “Nova” and now commonly called “NSU”, the university currently consists of 18 colleges and schools offering over 175 programs of study with more than 250 majors.
uk_condition = df['country']=='Satellite locations:'
df['country'][uk_condition] = "USA"
country_df = df.groupby('country').size()
for k in country_df.index:
print(k, country_df[k])
('Albania', 8)
('Argentina', 1)
('Australia', 49)
('Bahamas', 1)
('Bangladesh', 27)
('Botswana', 1)
('Brazil', 10)
('Bulgaria', 2)
('Canada', 666)
('Chile', 1)
('China', 5)
('Colombia', 1)
('Curacao', 1)
('Denmark', 8)
('Egypt', 1)
('England', 1274)
('Finland', 2)
('France', 8)
('Honduras', 1)
('India', 40)
('Iran', 9)
('Italy', 2)
('Japan', 112)
('Jordan', 2)
('Lebanon', 5)
('Mexico', 4)
('Nepal', 4)
('Netherlands', 4)
('Pakistan', 2)
('Philippines', 147)
('Puerto Rico', 2)
('Romania', 1)
('Rossija', 2)
('Russia', 3)
('Saudi Arabia', 1)
('Singapore', 4)
('South Africa', 7)
('South Korea', 7)
('Spain', 1)
('Sri Lanka', 4)
('Sweden', 24)
('Switzerland', 8)
('Taiwan', 1)
('Thailand', 4)
('Turkey', 4)
('USA', 13062)
('Utopia', 1)
Clean up values for the number of students
We need to clean the data for the number of students. Not all of the values are numeric, and many of them contain bits of text in addition to the actual number of the students. To figure out which entries need to be fixed, we need to use a Numeric facet:
df.describe()
| university | endowment | numFaculty | numDoctoral | country | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|---|---|
| count | 15534 | 15504 | 13541 | 602 | 15534 | 3166 | 15534 | 15183 | 15532 | 13830 |
| unique | 1085 | 1172 | 601 | 63 | 47 | 352 | 448 | 887 | 1104 | 698 |
| top | Pennsylvania State University | 1.708E9 | 8864 | 60 | USA | 3373 | 1855 | 800 | 77,179 Total | 800 |
| freq | 8960 | 4480 | 8960 | 192 | 13062 | 216 | 8970 | 651 | 896 | 564 |
df.numStudents.unique()
array(['70000', '27393', '21160', '894', '15553', '62801', '65234', nan,
'15424', '4533', '5756', '24424', '2426', '7730', '2987', '10477',
'13773', '14388', '14522', '32472', '40829', '17101', '7497',
'2400', '7306', '17500', '4463', '2200', '6448', '4863', '900+',
'13570', '4927', '32739', '1604', '2499', '13785', '16317', '339',
'1874', '10790', '4494', '4836', '4176', '4352', '30819', '6314',
'26851', '3251', '616', '49589', '50116', '3224', '52405',
'~50,000', '7773', '3785', '3822', '5000', '20712', '21000',
'21048', '7787', '17231', '18502', '6158', '11804', '36041',
'38912', '29390', '1207', '3090', '3249', '24370', '2654', '2815',
'15705', '14575', '1144', '10235', '1015', '3657', '1033', '1062',
'9840', '32762', '14806', '10623', '13438', '18900', '23420',
'3192', '2480', '12125', '4800', '30930', '7848', '5560', '12130',
'25063', '25277', '16567', '12270', '2566', '7881', '1972', '1779',
'2715', '4179', '3200', '971', '7538', '10133', '6214', '14196',
'35271', '11034', '17055', '14153', '998', '4238', '9251', '23500',
'4666', '17502', '11722', '47430', '4600', '9000', '7110', '3120',
'20655', '2766', '29290', '3740', '8394', '600', '3927', '1836',
'7313', '4061', '2073', '2183', '1315', '15484', '3345', '735',
'15872', '11308', '15889', '7885', '1066', '1331', '3574', '6840',
'1737', '11604', '6058', '1917', '5079', '23859', '23930', '2110',
'2640', '14000', '2942', '3483', '4854', '5930', '23175', '23855',
'2355', '9625', '4500', '1000', '779', '1760', '1885', '37641',
'3739', '17000', 'http://www.brocku.ca/athletics/quickfacts.php',
'20762', '21080', '757', '1116', '2000', '9748', '14177', '2242',
'2488', '19000', '2305', '16548', '16809', '38140', '13863', '4900',
'10363', '21016', '27008', '18,234 -', '26,101 -', '36000', '4200',
'21091', '110436', '18396', '18448', '9558', '7.07184E7',
'7.71264E7', '10000', '1650', '5097', '5471', '5008', '7542',
'8800', '1791', '23122', '30328', '6080', '2776', '14235', '2636',
'2744', '4250', '8094', '13600', '34767', '3709', '22125', '24875',
'2225', '9203', '27676', '8955', '25215', '29549', '30000', '11659',
'17', '3168', '17849', '22280', '19020', '800', '2725', '32275',
'33825', '4337', '3974', '12114', '23135', '3000', '3485', '29703',
'8831', '30303', '11476', '11842', '602', '8649', '1703', '3500',
'5201', '3719', '42099', '42595', '5760', '6082', '2175', '2231',
'22479', '4183', '47122', '5790', '4014', '28602', '42513', '1118',
'15405', '18442', '5033', '4600800.0', '10534', '28525', '55014',
'7751', '7755', '58698', '7567', '11201', '2100', '24531', '1500',
'1,500+', '46422', '46423', '754', '17290', '39165', '9300',
'41674', '42716', '42761', '42907', '49020', '12445', '19333',
'22405', '24662', '18572', '11593', '3209', '23162', '23590',
'8742', '5552', '5,552 total', '1415', '16822', '7942', '6957',
'11733', '28311', '5200', '13995', '14070', '30823', '31766',
'10688', '12557', '21225', '25313', '12024', '12683', '2124',
'5500', '5514', '5525', '12725', '9517', '35274', '37132', '450',
'23315', '24735', '10502', '20407', '8034', '1210', '46302',
'13959', '24849', '13490', '15265', '8606', '29462', '7615',
'24170', '8603', '8645', '9135', '8878', '9370', '29616', '22707',
'2334', '28018', '33585', '21210', '3439', '19700', '25890',
'26073', '9555', '13351', '13676', '4278', '35200', '14560', '7943',
'8005', '12714', '12002', '23761', '24977', '12400', '82', '3432',
'24594', '2648', '19890', '10820', '6101', '2565', '29894', '29952',
'5260', '22275', '16000', '20222', '21011', '37426', '19391',
'25700', '26960', '5379', '24593', '14765', '2900',
'faculty to student ratio: 12:1', '9150', '1600', '35204', '4000',
'47966', '1683', '~1,610', '363', '44', '32304', '6945', '51611',
'51721', '51853', '30540', '32500', '13183', '9940', '18475',
'38934', '57409', '24225', '22805', '30461', '44595', '49000',
'4991', '9339', '23085', '23336', '17455', '10383', '12000', '811',
'3246', '21827', '2282', '11646', '15642', '8810', '23600', '24192',
'8298', '23470', '13089', '19415', '19740', '41215', '2836', '3700',
'3770', '3829', '3721', '4525', '5365', '3050', '2345', '7700',
'7257', '2263', '19780', '2589', '2542', '29898', '2120', '2300',
'3600', '4384', '1748', '7928', '7005', '7277', '7740', '2270',
'1130.0', '1841.0', '6919', '47878', '34000', '9106', '8278',
'3378', '7131', '19966', '6964', '5809', '19664', '19993', '3420',
'2658', '2609', '1938', '2442', '42606', '2435', '10074', '20212',
'20,000+', '1460', '6276', '1308', '2719', '40000', '11065', '2660',
'3633', '80022011', '20487', '111329', '852', '131403', '24595',
'28', '1371', '3800', '23883', '3137', '33788', '28394', '30377',
'5.29092E7', '5.49E7', '14706', '720', '2674', '2886', '23103',
'8000', '10482', '6', '1890', '1872', '34255', '53337', '27523',
'18498', '11922', '6398', '15189', '70440', '72254', '23588',
'24378', '8985', '3461', '2', '27209', '22974', '11581', '47800',
'47954', '14769', '15195', '1771', '16355',
'One MEELLLLIOONNN DOLL HAIRS', '19500', '17499', '10894', '33500',
'15319', '3480', '28094', '8846', '6726', '27606', '20939', '20330',
'21535', '6647', '1454', '20643', '21329', '13925', '4496', '17261',
'17333', '21559', '630', '795', '6290', '8524', '33977', '44817',
'95833', '630 Dickinson School of Law', '800 College of Medicine',
'8,524 World Campus', '44,817 University Park', '795 Great Valley',
'95,833 Total', '33,977 Commonwealth Campuses',
'6,290 PA College of Tech', '25045', '29887', '31040', '27816',
'87274', '17999', '17950', '4197033329', '41710', '15649', '11956',
'28766', '28823', '2724', '45963', '978', '11180', '12312', '19721',
'5233', '29689', '4072', '11867', '38010', '18630', '27195',
'15657', '14820', '13381', '13893', '3245', '15064', '15473',
'7521', '5913', '5998', '33602', '31899', '39271', '39922', '33490',
'24125', '28994', '28290', '1115', '17351', '2284', '17533',
'18971', '39697', '39726', '27269', '19379', '13410', '2203',
'19728', '3005', '3045', '3540', '2459', '18004', '45126', '45954',
'2559', '15446', '32611', '56868', '28203', '20956', '3537', '6654',
'285392012', '15920', '34870', '8289', '25469', '10549', '18762',
'14713', '28091', '55115', '32653', '5152', '380', '14754', '7764',
'15951', '16040', '15536', '9799', '9352', '28457'], dtype=object)
float('5.29092E7')
52909200.0
df.numStudents = [str(i).replace('+', '').replace('~', '') for i in df.numStudents]
df.numStudents = [str(i).replace(',', '').replace('-', '').strip() for i in df.numStudents]
df.numStudents = [i.split(' ')[0] for i in df.numStudents]
# https://stackoverflow.com/questions/4138202/using-isdigit-for-floats
def isDigit(x):
try:
float(x)
return True
except ValueError:
return False
isDigit('1130.0')
True
str.isdigit('1130.0')
False
df['numStudents'] = df['numStudents'].apply(lambda x: np.float(x)
if isDigit(x)
else np.nan)
odds = {}
for i in df['numStudents']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
len(df)
15534
odds
{}
df.numStudents.iloc[0]
70000.0
df.numStudents.unique()[:10]
array([ 70000., 27393., 21160., 894., 15553., 62801., 65234.,
nan, 15424., 4533.])
df.numStudents.max(), df.numStudents.min()
(4197033329.0, 2.0)
# df.numStudents.astype('float')
# pd.to_numeric(df.numStudents)#, errors='ignore')
df.describe()
| numStudents | |
|---|---|
| count | 1.380000e+04 |
| mean | 3.934969e+05 |
| std | 3.585477e+07 |
| min | 2.000000e+00 |
| 25% | 1.065000e+03 |
| 50% | 1.068800e+04 |
| 75% | 3.397700e+04 |
| max | 4.197033e+09 |
Clean up values for the endowment
First remove the numeric facet for numStudents and create a new numeric facet for endowment. Select only the non-numeric values, as was done for the number of students. Already we see issues like “US$1.3 billion” and “US $186 million”
df['endowment']
0 15
2 121
3 4700000
4 16586100
5 16586100
6 40200750
7 40200750
8 40200750
9 40200750
10 40200750
11 40200750
12 40200750
13 40200750
14 40200750
15 40200750
16 40200750
17 40200750
18 562000000
19 562000000
22 NaN
23 NaN
24 NaN
25 NaN
26 NaN
27 1.3E7
28 1.0E7
29 3.5E8
30 4.5E8
31 0.0
32 0.0
...
74996 $2,17 billion
74997 $2,17 billion
74998 $2,17 billion
74999 $2,17 billion
75000 $2,17 billion
75001 $2,17 billion
75002 $2,17 billion
75003 $2,17 billion
75004 US $401.2 million
75006 US $213.2 million
75007 US $381 million
75008 US $64.5 million
75009 US $64.5 million
75010 US $64.5 million
75011 US $716.8 million
75012 US $716.8 million
75013 US $716.8 million
75014 US $716.8 million
75015 US $716.8 million
75016 US $716.8 million
75017 US $716.8 million
75018 US $716.8 million
75019 US $716.8 million
75020 US $716.8 million
75021 US $716.8 million
75022 US $716.8 million
75023 US $716.8 million
75024 US $716.8 million
75025 US $716.8 million
75026 US $716.8 million
Name: endowment, dtype: object
np.sum(odds.values())
0.0
odds = {}
for i in df['endowment']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
odds.items()[:3]
[('US$226 million', 1),
('US $6.44 billion', 16),
('1,5 billion \xe2\x82\xac', 1)]
np.float('1E6')
1000000.0
df.endowment = [str(i).replace('US $', '').replace('US$', '') for i in df.endowment]
df.endowment = [str(i).replace('USD$', '').replace('USD $', '') for i in df.endowment]
df.endowment = [str(i).replace('U.S. $', '').replace(',', '').strip() for i in df.endowment]
endowment = []
for i in df.endowment:
if i.__contains__('$'):
endowment.append(str(i).split('$')[1])
else:
endowment.append(i)
df.endowment = endowment
df.endowment = [str(i).replace(' million', 'E6').replace(' billion', 'E9').strip() for i in df.endowment]
df.endowment = [str(i).replace('million', 'E6').replace('billion', 'E9').strip() for i in df.endowment]
df.endowment = [str(i).replace(' Million', 'E6').replace(' Billion', 'E9').strip() for i in df.endowment]
df.endowment = [str(i).split(' ')[0] for i in df.endowment]
df.endowment = [str(i).replace('M', 'E6').strip() for i in df.endowment]
df.endowment = [str(i).replace(';', '').replace('+', '').strip() for i in df.endowment]
# df.endowment = [str(i).split('xbf')[1] for i in df.endowment]
# df.endowment = [str(i).split('xb')[1] for i in df.endowment]
# df.endowment = [str(i).split('xa')[1] for i in df.endowment]
After most of this has been cleaned up, select the non-numeric values, and delete them, just as was done for the numStudents.
df['endowment'] = df['endowment'].apply(lambda x: np.float(x)
if isDigit(x)
else np.nan)
df.describe()
| endowment | numStudents | |
|---|---|---|
| count | 1.490400e+04 | 1.380000e+04 |
| mean | 2.149103e+09 | 3.934969e+05 |
| std | 1.927573e+10 | 3.585477e+07 |
| min | 0.000000e+00 | 2.000000e+00 |
| 25% | 2.430000e+08 | 1.065000e+03 |
| 50% | 1.546000e+09 | 1.068800e+04 |
| 75% | 1.708000e+09 | 3.397700e+04 |
| max | 1.545840e+12 | 4.197033e+09 |
- 巴西雷亚尔的符号 R$
- CANADA DOLLARS C$
- 澳元的货币符号 A$
Both “million” and “Million” are in the values, so it’s useful to convert all the values to lowercase instead of cleaning this up twice.
df.head()
| university | endowment | numFaculty | numDoctoral | country | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Paris Universitas | 15.0 | 5500 | 8000 | France | NaN | 2005 | NaN | 25000 | 70000.0 |
| 2 | Lumi%C3%A8re University Lyon 2 | 121.0 | NaN | 1355 | France | NaN | 1835 | 7046 | 14851 | 27393.0 |
| 3 | Confederation College | 4700000.0 | NaN | NaN | Canada | NaN | 1967 | not available | pre-university students; technical | 21160.0 |
| 4 | Rocky Mountain College | 16586100.0 | NaN | NaN | USA | NaN | 1878 | 66 | 878 | 894.0 |
| 5 | Rocky Mountain College | 16586100.0 | NaN | NaN | USA | NaN | 1878 | 66 | 878 | 894.0 |
Others
numFaculty, numDoctoral, numStaff, numPostgrad, numUndergrad, established
numFaculty
df.numFaculty = [str(i).replace('Total: ', '').replace(',', '') for i in df.numFaculty]
df.numFaculty = [str(i).replace('>', '').replace('~', '') for i in df.numFaculty]
df.numFaculty = [str(i).split(' ')[0] for i in df.numFaculty]
df['numFaculty'] = df['numFaculty'].apply(lambda x: np.float(x)
if isDigit(x)
else np.nan)
odds = {}
for i in df['numFaculty']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
odds.items()
[]
numDoctoral
odds = {}
for i in df['numDoctoral']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
odds.items()
[('available', 1),
('N\\A', 27),
('not available', 40),
('N.A', 16),
('~25', 4)]
df.numDoctoral = [str(i).replace('~', '') for i in df.numFaculty]
df['numDoctoral'] = df['numDoctoral'].apply(lambda x: np.float(x)
if isDigit(x)
else np.nan)
numStaff
odds = {}
for i in df['numStaff']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
odds.items()
[('incl. 1,403 academics and 150 researchers', 2),
('Total: 873', 48),
('Approximately 7,170', 1),
('approximately 30', 1),
('167 full-time academic faculty, \n596 non-academic staff', 4),
('Around 120', 27),
('~500', 4),
('190 researchers & lecturers, 153 administrative & technical staff', 2),
('Approximately 500', 1),
('4,478 employees', 64),
('Around 5,000', 48),
('>21,000', 2),
('?', 1),
('~100', 4),
('full-time, part-time', 1),
('Total: 1,608', 2),
('Total: 1,600', 16),
('Full-time: 1,469', 2),
('156 full-time; 229 part-time', 1),
('Part-time: 139', 2),
('960 full-time, 460 part-time', 16),
('appx. 20', 8),
('~', 1)]
df.numStaff = [str(i).replace('Total: ', '').replace(',', '') for i in df.numStaff]
df.numStaff = [str(i).replace('>', '').replace('~', '') for i in df.numStaff]
df.numStaff = [str(i).replace('Around ', '').replace('appx. ', '') for i in df.numStaff]
df.numStaff = [str(i).replace(' employees', '').replace('Approximately ', '') for i in df.numStaff]
df.numStaff = [str(i).replace('Full-time: ', '').replace('Part-time: ', '') for i in df.numStaff]
df.numStaff = [str(i).replace('approximately ', '') for i in df.numStaff]
df.numStaff = [str(i).split(' ')[0] for i in df.numStaff]
df['numStaff'] = df['numStaff'].apply(lambda x: np.float(x)
if isDigit(x)
else np.nan)
numPostgrad
odds = {}
for i in df['numPostgrad']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
odds.items()
[('268 full-time MBA', 24),
('approx. 300', 1),
('~650', 4),
('n/a', 1),
('Aprx. 2,000', 2),
('630 Dickinson School of Law', 640),
('120+', 8),
('795 Great Valley', 640),
('Does not offer postgraduate studies', 1),
('~3,914', 1),
('4,937 full-time, 1,446 part-time', 2),
('800 College of Medicine', 640),
('not available', 1),
('~3,200', 2),
('Masters of Business Administration in Community Economic Development', 20),
('Some postdoctoral students and visiting scholars', 1),
('postgraduate level degree available', 1),
('~160', 3),
('142 Ph.D. students', 2),
('1,682 Commonwealth Campuses', 640),
('available', 1),
('71 MLHR', 24),
('14,020 Total', 640),
('Approximately 1000', 1),
('Approx. 600', 1),
('----', 4),
('~500', 4),
('~5,500', 2),
('~60', 4),
('325 part-time MBA', 24),
('over 1,300', 1),
('N\\A', 9),
('none', 1),
('6,223 University Park', 640),
('ca. 3,230', 2),
('95 MAcc', 24),
('9,957 \xe2\x80\x93 Vancouver', 24),
('531 \xe2\x80\x93 Okanagan', 24),
('3,890 World Campus', 640),
('TBD', 2)]
df.numPostgrad = [str(i).replace('~', '').replace(',', '') for i in df.numPostgrad]
df.numPostgrad = [str(i).replace('approx. ', '').replace('Approx. ', '') for i in df.numPostgrad]
df.numPostgrad = [str(i).replace('Approximately ', '').replace('Aprx. ', '') for i in df.numPostgrad]
df.numPostgrad = [str(i).replace('+', '').replace('over', '') for i in df.numPostgrad]
df.numPostgrad = [str(i).split(' ')[0] for i in df.numPostgrad]
df['numPostgrad'] = df['numPostgrad'].apply(lambda x: np.float(x)
if isDigit(x)
else np.nan)
numUndergrad
odds = {}
for i in df['numUndergrad']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
odds.items()
[('4,747 full-time', 96),
('over 2,000', 1),
('Approximately 10,000', 1),
('2,000+', 8),
('approximately 1,500', 1),
('n/a', 1),
('Aprx. 2,000', 2),
('School of Liberal Arts; School of Science & Technology; School of Graduate & Professional Studies; Shannon School of Business',
20),
('approx. 2,000', 1),
('36,518 \xe2\x80\x93 Vancouver', 24),
('~25,000', 2),
('65 per year', 1),
('77,179 Total', 896),
('approx. 1,200', 8),
('Approx. 12,000', 2),
('38,594 University Park', 896),
('32,295 Commonwealth Campuses', 896),
('Approximately 2,300', 1),
('7,004 \xe2\x80\x93 Okanagan', 24),
('~400', 1),
('pre-university students; technical', 1),
('Around 10,000', 2),
('available', 3),
('21,726 -', 24),
('None', 1),
('900+', 1),
('475 Resident Undergraduates', 1),
('ca. 3,046', 2),
('Approx. 7,100', 1),
('6,290 PA College of Tech', 896),
('4,634 World Campus', 896),
('28,477 full-time, 2,102 part-time', 2),
('none', 1),
('approx. 2,150', 4),
('Approximately 730', 1),
('~13,000', 2),
('~2,000', 4),
('diploma, degree available', 1),
('Approx. 13,000', 1),
('2,000 traditional', 1),
('~1,560', 1),
('???', 1),
('~1,550', 4)]
df.numUndergrad = [str(i).replace('~', '').replace(',', '') for i in df.numUndergrad]
df.numUndergrad = [str(i).replace('approx. ', '').replace('Approx. ', '') for i in df.numUndergrad]
df.numUndergrad = [str(i).replace('Approximately ', '').replace('Aprx. ', '') for i in df.numUndergrad]
df.numUndergrad = [str(i).replace('approximately ', '').replace('Around ', '') for i in df.numUndergrad]
df.numUndergrad = [str(i).replace('+', '').replace('over', '') for i in df.numUndergrad]
df.numUndergrad = [str(i).split(' ')[0] for i in df.numUndergrad]
df['numUndergrad'] = df['numUndergrad'].apply(lambda x: np.float(x)
if isDigit(x)
else np.nan)
established
df.established
0 2005
2 1835
3 1967
4 1878
5 1878
6 1901
7 1901
8 1947
9 1947
10 1963
11 1963
12 1963 - university status
13 1963 - university status
14 1947 - four-year college
15 1947 - four-year college
16 1901 -
17 1901 -
18 1924
19 1924
22 1970
23 1918-05-01
24 1925
25 Established 1985
26 Chartered 1984
27 1994
28 1947
29 1948
30 1878
31 2004-09-30
32 2004-09-30
...
74996 1848
74997 1848
74998 1848
74999 1848
75000 1848
75001 1848
75002 1848
75003 1848
75004 1881-08-28
75006 1855-10-15
75007 1911
75008 1964
75009 1964
75010 1964
75011 1851
75012 1851
75013 1851
75014 1851
75015 1851
75016 1851
75017 1851
75018 1851
75019 1851
75020 1851
75021 1851
75022 1851
75023 1851
75024 1851
75025 1851
75026 1851
Name: established, dtype: object
odds = {}
for i in df['established']:
if not isDigit(i):
try:
odds[i] += 1
except:
odds[i] = 1
odds.items()[:5]
[]
import re
def getYear(s):
try:
match = re.match(r'.*([1-3][0-9]{3})', s)
return np.int(match.group(1))
except:
return np.nan
df.established = [getYear(i) for i in df.established]
df.describe()
| endowment | numFaculty | numDoctoral | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|
| count | 1.490400e+04 | 1.348700e+04 | 1.348700e+04 | 3.161000e+03 | 15186.000000 | 1.513800e+04 | 1.550000e+04 | 1.380000e+04 |
| mean | 2.149103e+09 | 8.695432e+03 | 8.695432e+03 | 1.057127e+04 | 1865.196036 | 1.104538e+04 | 2.762582e+05 | 3.934969e+05 |
| std | 1.927573e+10 | 1.286384e+05 | 1.286384e+05 | 2.483439e+05 | 65.865596 | 3.622826e+05 | 2.581618e+07 | 3.585477e+07 |
| min | 0.000000e+00 | 1.000000e+00 | 1.000000e+00 | 2.000000e+00 | 1066.000000 | 0.000000e+00 | 0.000000e+00 | 2.000000e+00 |
| 25% | 2.430000e+08 | 1.953000e+03 | 1.953000e+03 | 1.592000e+03 | 1855.000000 | 8.000000e+02 | 6.290000e+03 | 1.065000e+03 |
| 50% | 1.546000e+09 | 8.864000e+03 | 8.864000e+03 | 2.799000e+03 | 1855.000000 | 3.067000e+03 | 1.782100e+04 | 1.068800e+04 |
| 75% | 1.708000e+09 | 8.864000e+03 | 8.864000e+03 | 5.000000e+03 | 1881.000000 | 6.223000e+03 | 3.667500e+04 | 3.397700e+04 |
| max | 1.545840e+12 | 1.407201e+07 | 1.407201e+07 | 1.280201e+07 | 2012.000000 | 2.998201e+07 | 3.198523e+09 | 4.197033e+09 |
University
df['university'].unique(), df['university'].unique().size
(array(['Paris Universitas', 'Lumi%C3%A8re University Lyon 2',
'Confederation College', ..., 'University of San Francisco',
'Loyola Marymount University', 'Nova Southeastern University'], dtype=object),
1085)
# university_df = df.groupby('university').size()
# for k in university_df.index:
# print(k, university_df[k])
df.university = [str(i).replace('%2C', '').replace(',', '') for i in df.university]
df.university = [str(i).replace('%C3%89', 'e').replace('%C3%A9', 'e') for i in df.university]
df.university = [str(i).replace('%E2%80%93', ' ').replace('%22', '') for i in df.university]
df.university = [str(i).replace('%C3%A3', 'a').replace('%C3%A7', 'c') for i in df.university]
df.university = [str(i).replace('%C3%AA', 'e').replace('%C3%BA', 'u') for i in df.university]
df.university = [str(i).replace('%C3%A1', 'a').replace('%C3%B3', 'o') for i in df.university]
df.university = [str(i).replace('%CA%BB', "'").replace('%C4%81', 'a') for i in df.university]
df.head()
| university | endowment | numFaculty | numDoctoral | country | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Paris Universitas | 15.0 | 5500.0 | 5500.0 | France | NaN | 2005.0 | NaN | 25000.0 | 70000.0 |
| 2 | Lumi%C3%A8re University Lyon 2 | 121.0 | NaN | NaN | France | NaN | 1835.0 | 7046.0 | 14851.0 | 27393.0 |
| 3 | Confederation College | 4700000.0 | NaN | NaN | Canada | NaN | 1967.0 | NaN | NaN | 21160.0 |
| 4 | Rocky Mountain College | 16586100.0 | NaN | NaN | USA | NaN | 1878.0 | 66.0 | 878.0 | 894.0 |
| 5 | Rocky Mountain College | 16586100.0 | NaN | NaN | USA | NaN | 1878.0 | 66.0 | 878.0 | 894.0 |
len(df)
15534
Deduplicate entries 2.0
df = df.drop_duplicates()
len(df)
4919
df.head()
| university | endowment | numFaculty | numDoctoral | country | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Paris Universitas | 15.0 | 5500.0 | 5500.0 | France | NaN | 2005.0 | NaN | 25000.0 | 70000.0 |
| 2 | Lumi%C3%A8re University Lyon 2 | 121.0 | NaN | NaN | France | NaN | 1835.0 | 7046.0 | 14851.0 | 27393.0 |
| 3 | Confederation College | 4700000.0 | NaN | NaN | Canada | NaN | 1967.0 | NaN | NaN | 21160.0 |
| 4 | Rocky Mountain College | 16586100.0 | NaN | NaN | USA | NaN | 1878.0 | 66.0 | 878.0 | 894.0 |
| 6 | Idaho State University | 40200750.0 | 838.0 | 838.0 | USA | 1269.0 | 1901.0 | 2661.0 | 12892.0 | 15553.0 |
df.describe()
| endowment | numFaculty | numDoctoral | numStaff | established | numPostgrad | numUndergrad | numStudents | |
|---|---|---|---|---|---|---|---|---|
| count | 4.585000e+03 | 3.650000e+03 | 3.650000e+03 | 2.159000e+03 | 4677.000000 | 4.568000e+03 | 4.887000e+03 | 3.734000e+03 |
| mean | 3.128695e+09 | 1.101300e+04 | 1.101300e+04 | 1.302496e+04 | 1879.911268 | 2.654159e+04 | 8.144919e+05 | 1.390889e+06 |
| std | 3.311783e+10 | 2.472490e+05 | 2.472490e+05 | 3.004688e+05 | 95.221953 | 6.592566e+05 | 4.597518e+07 | 6.892540e+07 |
| min | 0.000000e+00 | 1.000000e+00 | 1.000000e+00 | 2.000000e+00 | 1066.000000 | 0.000000e+00 | 0.000000e+00 | 2.000000e+00 |
| 25% | 2.900000e+07 | 5.315000e+02 | 5.315000e+02 | 1.178000e+03 | 1855.000000 | 1.305000e+03 | 4.634000e+03 | 7.542000e+03 |
| 50% | 1.892540e+08 | 1.099000e+03 | 1.099000e+03 | 2.211000e+03 | 1887.000000 | 3.364000e+03 | 1.348000e+04 | 1.933300e+04 |
| 75% | 1.295000e+09 | 3.694000e+03 | 3.694000e+03 | 4.478000e+03 | 1924.000000 | 6.614250e+03 | 2.332800e+04 | 2.570000e+04 |
| max | 1.545840e+12 | 1.407201e+07 | 1.407201e+07 | 1.280201e+07 | 2012.000000 | 2.998201e+07 | 3.198523e+09 | 4.197033e+09 |
plt.matshow(df.corr())
plt.show()
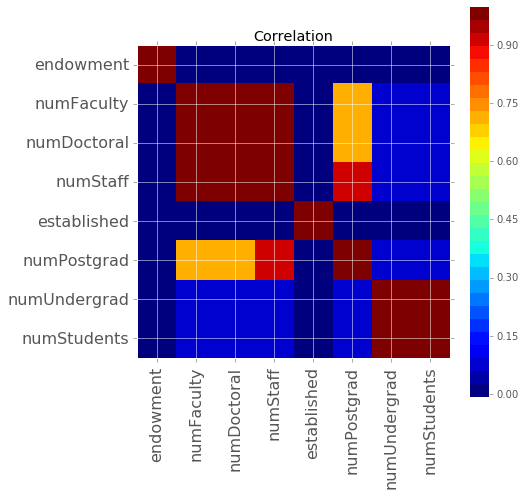
def correlation_matrix(df):
from matplotlib import pyplot as plt
from matplotlib import cm as cm
fig = plt.figure(figsize=(7, 7),facecolor='white')
ax1 = fig.add_subplot(111)
cmap = cm.get_cmap('jet', 30)
cax = ax1.imshow(df.corr(), interpolation="nearest", cmap=cmap)
ax1.grid(True)
plt.title('Correlation')
labels=['','endowment','numFaculty','numDoctoral','numStaff',\
'established','numPostgrad','numUndergrad','numStudents']
ax1.set_xticklabels(labels,fontsize=16, rotation = 90)
ax1.set_yticklabels(labels,fontsize=16)
# Add colorbar, make sure to specify tick locations to match desired ticklabels
fig.colorbar(cax)
plt.show()
correlation_matrix(df)
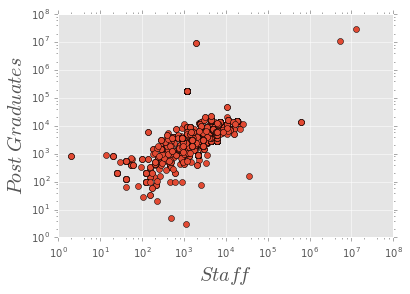
plt.plot(df.numStaff, df.numPostgrad, 'o')
plt.yscale('log')
plt.xscale('log')
plt.xlabel('$Staff$', fontsize = 20)
plt.ylabel('$Post\;Graduates$', fontsize = 20)
plt.show()
Write data
df.to_csv(‘universityDataClean.csv’, index = False)
Jupyter Notebook
本文所使用到的所有代码见 nbviewer。



Leave a Comment